


Have you ever toyed with the idea of what machine learning actually does? If machine learning is a pack horse for information processing, a neural network is the carrot that draws the horse forward. For a system to truly be able to learn, it should not be programmed to perform a particular task; instead, it should be programmed to learn to perform the task. To do so, the system needs to use a more refined form of machine learning called deep learning which is based on neural networks. With neural networks, the system can independently perceive patterns in the data to learn how to perform a task.
Neural networks, or more specifically, artificial neural networks (ANN), are processing devices. They can be algorithms or actual hardware – that are loosely modelled after the neuronal structure of the brain’s cerebral cortex but on smaller scales.
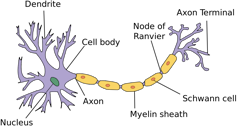
The origin of modern ANNs is based on a mathematical model of the neuron called the perceptron, introduced by Frank Rosenblatt in 1957. As can be seen below, the model closely resembles the structure of the neuron with inputs resembling dendrites (a short extension of a neuron that transmits electrochemical signals from one neuron to another).
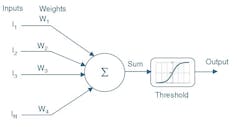
In the original model made by Warren McCulloch and Walter Pitts, the inputs were either 0 or 1. Each dendrite/input also had a weight of +1 and -1. The input was thus multiplied by its weight, and the sum of the weighted inputs was then fed to a model. The perceptron thus takes several binary inputs, (I1, I2… IN), and produces a single binary output which is the weighted average of the multiple inputs. If the cumulated output is greater than a set threshold level, then the model delivers a certain output. In other words, output = 0 if the result is smaller than or equal to the threshold; output = 1 if the result is larger than to the threshold.
The power of layers
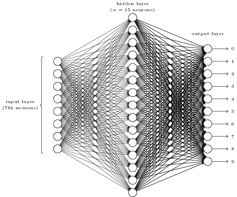
Based on this initial schema, the perceptron model allows the inputs to the neurons and the weights to take on any value. ANN is thus nothing more than interconnected layers of a perceptron, as seen below:
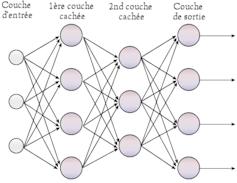
By varying the weights and the threshold, we can get different models of decision-making. The outputs from a hidden layer can also be fed into another hidden layer of the perceptron. The first layer of a perceptron makes very simple decisions, by weighing the input evidence. These outputs are then fed to a second layer, which make a decision by weighing up the results from the first layer.
By following this method, a perceptron in the second layer can decide at a more complex and more abstract level than the perceptron in the first layer. If a third layer is involved, then the decisions can be made by those perceptrons will be even more complex. In this way, a “deep”, many-layer network of perceptrons can engage in sophisticated decision making. The greater the number of layers of perceptrons, the higher the decision-making ability, something that is applicable in a number of areas.
But why is it only now that deep learning is flourishing? One answer is that with the increase of computing power, it is possible to process input and output of results quickly. Interestingly, it was discovered in 2009 that the specialised chips used in PCs and video-game consoles to generate complex graphics were also well-suited to model neural networks. In addition, the rise of the Internet has made a vast amount of documents, videos and photos available for training purposes.
Deep learning and ANNs have transformed the world of artificial intelligence in recent years. More importantly they have played a significant role in improving the “intelligence” of AI. Tasks and abilities that were once considered the domain of humans are now being performed by deep neural networks. Deep learning is what allowed the machine to beat the world’s best Go player.
Business implications
What this shows us is that with massive amounts of data and computational power, machines can now recognize objects, translate speech, train themselves to identify complex patterns, learn how to devise strategies and make contingency plans in real time. Artificial intelligence is not just able to do tasks. It is starting to think.
Business are now looking at using deep learning in ports and airports to scan for concealed weapons. In finance, the world of algorithmic trading and asset management has been moving increasingly toward deep learning. Asset managers are using deep learning to look for overall patterns in multiple data sources such as shipping receipts, customer feedback on Twitter, speeches by Federal Reserve members, to name just a few. Note that since most of this data is unstructured, it would be close to impossible to make simple predictive models with regular statistical models.
But with deep learning, the unlabelled data can be analysed, patterns founds and insights gained. This helps in getting a better understanding of the correlations between various data sources and in making predictions. For example, by applying deep-learning methods to finance, researchers have been able to produce more useful results than standard statistical and economic models. Deep learning has been used to detect and exploit interactions in the data that are, at least currently, invisible to any existing financial economic theory.
In the next article, we will see another related development called natural language processing and affective computing before bringing all of them together under the umbrella of artificial intelligence.
The research of this article is sponsored by KPMG/ESCP Europe Chair Governance, Strategy, Risks, and Performance. Terence Tse and Mark Esposito are the authors of “Understanding How the Future Unfolds: Using DRIVE to Harness the Power of Today’s Megatrends”. Kary Bheemaiah is the author of “The Blockchain Alternative: Rethinking Macroeconomic Policy and Economic Theory”.