

One key goal of the Affordable Care Act (ACA) was to lower health care costs by giving consumers more choice over their insurer.
Economic theory suggests that when consumers make informed and active choices in a competitive market, companies respond by lowering prices and improving the quality of their offerings.
But theory aside, empirical research shows consumers don’t actually behave this way in practice, particularly in complex markets like health insurance.
This reality makes it a lot harder for government policy to effectively curb the cost of health care (some of which it pays for) and reduce premiums. It also means many individuals are probably paying a lot more than they should on health insurance.
So is there anything we can do to help people make better insurance decisions?
In a recent paper I coauthored with fellow Berkeley economist Jonathan Kolstad, we assessed how personalized data could help consumers do just that and as a result make health markets more efficient.
Many options, much confusion
Controlling health care spending – which hit US$3 trillion a year for the first time in 2014 – remains an especially high priority for policymakers. Spending growth slowed below historical averages around the time the ACA was passed but has since accelerated.
Federal and state regulators crafted the ACA exchanges to encourage insurers to compete on price and quality while offering consumers a wider range of options.
Several Medicare markets, such as Plan D prescription drug coverage, do the same, while companies that provide health insurance are also increasingly offering more options to their employees via privately facilitated exchanges.
But giving individuals more options is only a first step. Research shows that consumers make mistakes while actively shopping because of a lack of available information, limited understanding of insurance or just the overall hassle of it. These difficulties exist whether the choices are just a few or several dozen.
This leads consumers to leave hundreds or even thousands of dollars on the table. It also contributes to “choice inertia,” in which consumers may make smart initial choices but fail to follow up and actively reconsider them as new information emerges or conditions change. That can also cost them a lot of money over time.
In our research, we examined how we might solve these problems.
Targeted consumer recommendations
One way involves providing consumers with user-specific plan recommendations based on detailed data about their personal health care needs and preferences.
The personalized information is based on an individual’s expected health risks, financial risk appetite and physician preferences. These policies highlight the best options for a given consumer by associating each choice with metrics that consumers readily understand and care about, such as their expected spending in each plan in the upcoming year.
The broad goal is to harness the power of consumer data and technology to make effective recommendations in insurance markets, similar to what we already see elsewhere. For example, Amazon uses your purchase history and browsing data to make recommendations about what additional products you might like, while Google processes vast amounts of information to tailor customized ads.
There has already been some progress toward implementing these kinds of conditions in insurance markets.
A key concern, however, is that such policies are not effective enough. Empirical evidence suggests that even if you lead consumers to the well of information, you can’t necessarily force them to drink.
Smart defaults may be the answer
So if providing personalized data and recommendations isn’t enough to help consumers make better choices, could a more aggressive policy be effective?
One way is through “smart defaults,” which automatically place consumers into preferable plans based on user-specific information. Instead of requiring people to act on recommendations, the optimal option is selected for them.
These smart defaults would be carefully targeted based on each individual’s own data, but they’d also be nonbinding, allowing consumers to switch to another option at any time.
The smart defaults we proposed in our paper are based on detailed data on consumer-specific demographics and health needs and a model of health plan value. The smart defaults would work by using data such as past medical claims and demographic info to assess whether it would make sense to switch to another plan. An economic model and specific value thresholds are set up at the outset to govern how much risk to take and how much savings must be gained from a switch.
That economic model, implemented with a computer algorithm, would consider financial gains, exposure to risks in the event of a major medical incident and access to the right physicians.
If the right conditions are met (more or less aggressive), the consumer is defaulted into a new plan. The figure at right illustrates the process in more detail.
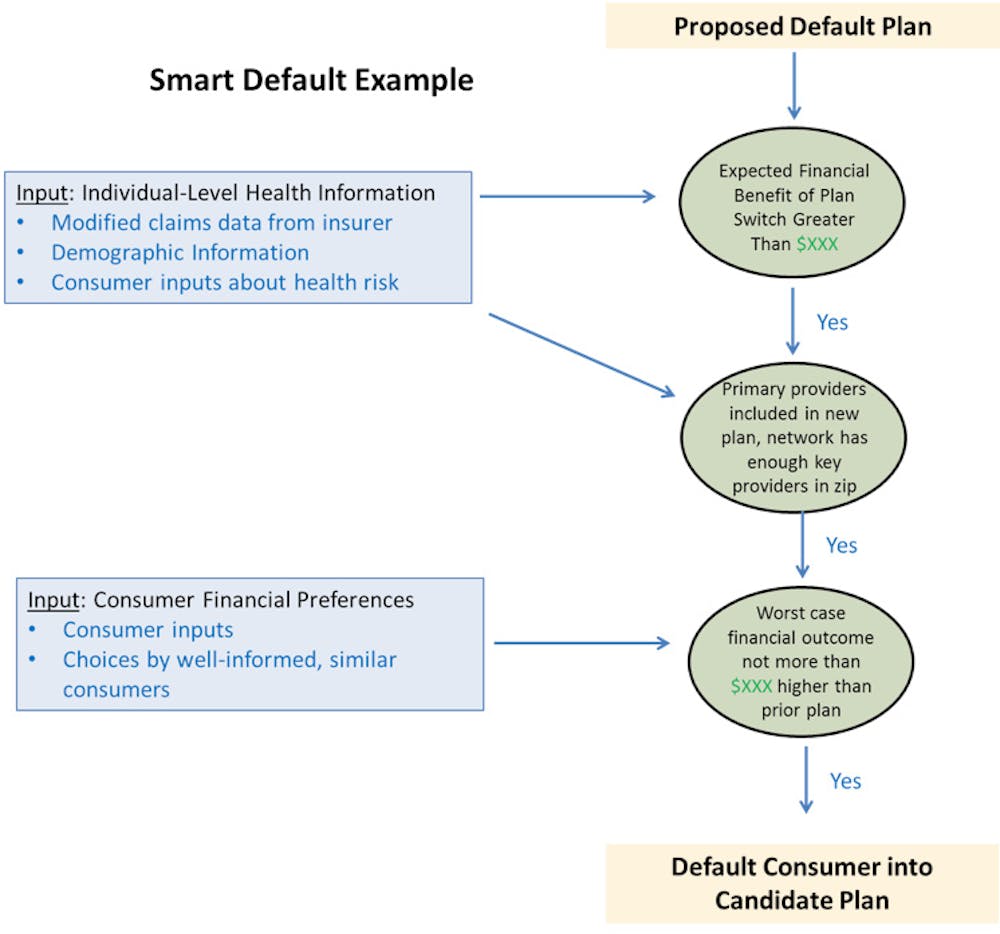
For example, consider a diabetic patient enrolled in a plan with an annual premium of $4,000 and access to a specific set of physicians. On top of the premium, the patient is anticipated to spend another $2,000 per year in cost-sharing – deductibles, copays for appointments, prescriptions, equipment to test blood sugar and other services – up to a maximum of $8,000.
The smart default algorithm would first consider whether there was an alternative in the market that would “meaningfully lower” the patient’s annual spending. If the threshold was set at $1,000, the algorithm would search for an option that anticipates the patient would spend no more than $5,000 in premiums and cost-sharing.
Two more conditions must also be met: the physicians the patient sees would have to be in the plan’s network and the option could not expose him or her to too much additional financial risk (maximum for cost-sharing). So if the financial risk threshold were set at $500, then the alternative plan would have to max out at no more than $8,500.
The patient would then be auto-enrolled in the plan, with anticipated savings of $1,000 a year and a worst case scenario of only $500 in additional spending.
Thus far, such defaults have been used only sparingly in health insurance markets. But in other contexts, such as helping employees choose how much to contribute to pension plans, smart defaults have proven remarkably effective at improving choice quality.
If you have a 401(k) plan at work, for example, there’s a good chance this smart default system has been used to put you in the best plan for your circumstance. This works for retirement savings now because the options are simpler and there’s plenty of data.
Problems with smart defaults
So why aren’t we using smart defaults more broadly in health insurance markets right now?
For starters, policymakers and employers are likely reluctant to implement policies that appear to drive insurance choices in such a forceful manner. For example, if the default settings are overly aggressive, many consumers could be auto-enrolled into plans that make them worse off – even if the average person would be better off.
A possible solution to this is that the thresholds for auto-enrollment could be set very conservatively, so that only consumers with substantial expected gains are affected (though this also would reduce the potential benefits).
A more fundamental problem, however, is the lack of data. Unfortunately, regulators often don’t have the kind of real-time consumer data on personalized health risks, insurance usage and demographics necessary to effectively implement smart default policies in a precise manner (as is true in pension choices). One reason is that insurance companies often refuse to share their data with regulators on the grounds that they are proprietary, and the Supreme Court has upheld their stance.
In such cases, smart defaults are still possible but provide less value to consumers and must be more conservative in their implementation.
Additional considerations
Little is known about the effects of market competition when consumer choices are driven by algorithms rather than by a more free-flowing and natural process.
For example, could insurers try to systematically exploit known features of the algorithm to push more people into their plans (as with advertisers interacting with Google)? Or will individuals end up being less engaged in the process of choosing their own insurance, which means they’ll be less informed about what benefits they actually have and the associated risks?
Understanding the consequences of letting computer algorithms make consumer choices will be crucial in assessing whether implementing a policy like smart defaults could work in helping consumers make better choices with minimal downsides. But it won’t be possible until insurers begin to share more detailed data with regulators.