




Bankers aim to maximise profits. Scientists aim to understand reality. But Mike Peacey of the University of Bristol suggests, based on a new model he has just published in Nature, that both professionals are equally likely to conform to whatever views are prevalent, whether they are right or wrong.
In the past decade scientists have raised serious doubts about whether science is as self-correcting as is commonly assumed. Many published findings, including those in the most prestigious journals, have been found to be wrong. One of the reasons is that, once a hypothesis becomes widely accepted, it becomes very difficult to refute it, which makes it, as Jeremy Freese of Northwestern University recently put it, “vampirical more than empirical – unable to be killed by mere evidence”.
There are three possibilities to explain why scientists converge on mistaken conclusions. First, as humans, scientists try to be rational but remain stuck on certain views in the face of contrary evidence. Second, some scientists make up data to further their careers, as happened in a high profile case last year. Third, the “publish or perish” culture forces scientists to consciously or unconsciously gravitate towards results that support their conclusions.
At the heart of science’s attempt to be self-correcting is the peer review system. The hope is that scientists’ aim to understand the world will guide them in evaluating the research, and that multiple independent reviews will get rid of some of the biases that usually affect the authors and the reviewers.
Sadly the peer review system does not always live up to its high aims. Some have called to abandon the system, while others insist that, like democracy, it is the least worst system on offer. “Peer review isn’t as bad as many think,” Peacey said. He and his colleagues decided to investigate what some of its faults are and how they could be fixed. They built a computer model to understand how scientists may behave based on some simplified parameters.
Subjectivity wins
Assume a group of scientists is deciding between Hypothesis A and Hypothesis B. Each scientist will have some probability of leaning towards one hypothesis or the other. The computer model begins when a scientist submits a manuscript based on one of these views to a journal. To keep things simple, editors will always pass this manuscript on for peer review. Now the reviewers need to decide whether the manuscript should be published. After which they will also need to decide which hypothesis should they lean towards in their own future submission.
(In reality one of the hypothesis may be correct, if herding occurred on the correct one it won’t be harmful. But that wasn’t the point of the experiment and thus the researchers gave no value judgement to a hypothesis.)
They ran the model in three different conditions. In M1 scientists were allowed to use their own subjective and unpublished results to evaluate the manuscript. In M2 scientists were forced to remain as objective as possible. In M3 all manuscripts were published without peer review.
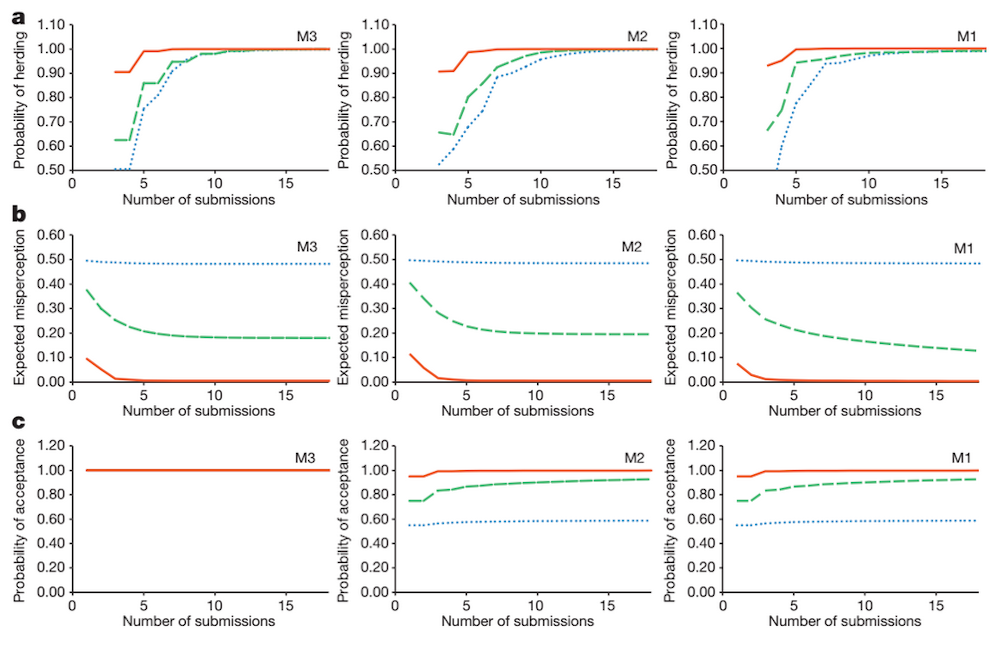
They looked at the probability of three outcomes – herding (scientists will submit manuscript on hypothesis they disagree with but others agree with), “misperception” (distance between scientific perception and the truth) and acceptance for publication. On all three outcomes M1 appears to win. In that model herding took the most time, misperception was at its lowest and the probability of acceptance was about the same.
“The simple conclusion is that subjective views of scientists should be encouraged in peer-review,” Peacey said. A moderate degree of subjectivity is optimal, further analysis revealed. “This doesn’t happen that much. A lot of journals insist reviewers be as objective as possible in their analysis. Instead, questions like ‘how interesting do you think this paper is?’ or ‘do you think this paper will make significant impact on the field?’ should be asked.”
Herd mentality
The most troubling aspect, however, is that herding occurs in all models. Bankers, particularly, have been blamed for making bad decisions because of herding.
Behavioural economics shows that one way to counter herding is to aggregate private signals across markets, rather than the public signals (buying or selling) that are used currently. For science this would mean a more open system of review, including that which involves peer review after a paper is published.
This form of herding should affect all journals that do not include subjective parameters. John Hollmwood of the University of Nottingham said, “High impact factors for journals may well be the outcome of herding. It would be interesting to find out if low impact factor journals offer greater heterogeneity.” Harry Collins of Cardiff University said, “I doubt this sort of herding occurs among top scientists, who are a much smaller group than top journals, which I believe are not publishing the best ideas out there.”
“But what is described is a model not an empirical study,” Holmwood said. And that is one limitation of the study: human behaviour is very difficult to model.
The other limitation might be that herding is not a new phenomenon, and Peacey’s conclusions agree with other scientific literature on human behaviour. The fact that this study was published in the prestigious journal Nature might itself be an example of herding. Or perhaps, for once, scientists are actually closer to a truth.