

While most medication is prescribed and taken without any problems, 237m medication errors still take place every year in England alone. Most of these errors are minor and might not reach a patient, but some can make people very unwell or even be fatal. There may be several reasons why these mistakes happen, but my research looks into the problems that similar looking or sounding names of medication can cause. Over 8,000 generic names and thousands more brand names are used for medicines in the UK alone, so it isn’t surprising that many medication names are very similar and can be confused.
In one English language case of a lookalike name confusion error, reported in 2004, a patient was prescribed morphine but was mistakenly administered hydromorphone – which is five times stronger than morphine. In effect, it caused a dangerous and fatal overdose and the patient sadly died on their way home from hospital.
Looking into this case, the complexity of medication error is revealed. When the nurse was getting the medication out of the cupboard, she was distracted by another patient climbing off a stretcher and quickly popped the ampoule in her pocket. She returned, filled the syringe, forgot the reconciliation record, and gave the medication to the patient. She remembered seeing “morph 10” on the ampoule and presumed she had picked up the correct medication (morphine).
In fact, she had picked up hydromorphone because the ampoules were almost identical, and the names were very similar. Hydromorphone was not normally stored in that cupboard, and the hospital had no guidelines in place for monitoring patients after taking narcotics. This created a perfect storm for error.
Human errors
Popular human error theory separates error reduction strategies into the person approach and the system approach. The person approach would blame the nurse, proposing that she was distracted, careless or even negligent. The system approach would look at the wider context. Was the ward understaffed? Why were key monitoring guidelines not in place? Why were medications with similar names but different strengths stored together and presented in lookalike packaging? This second approach applies what is known as a Swiss cheese model to error reduction. Humans are fallible, and we need to have multiple system defences – slices of cheese – to guard against an error getting through to a patient.
There are lots of ways to reduce confusion errors between lookalike medication names, for example, computerised prescribing systems or barcoding. Another way is to use different fonts or text formats to print and display similar names. Tallman lettering, for instance, uses capital letters to distinguish between similar parts of names – as in hydrOXYzine and hydrALAzine. Distractions and interruptions can also be reduced, and understaffing and heavy workloads avoided. We could also ensure that medications with lookalike or soundalike names and packaging are not stored together.
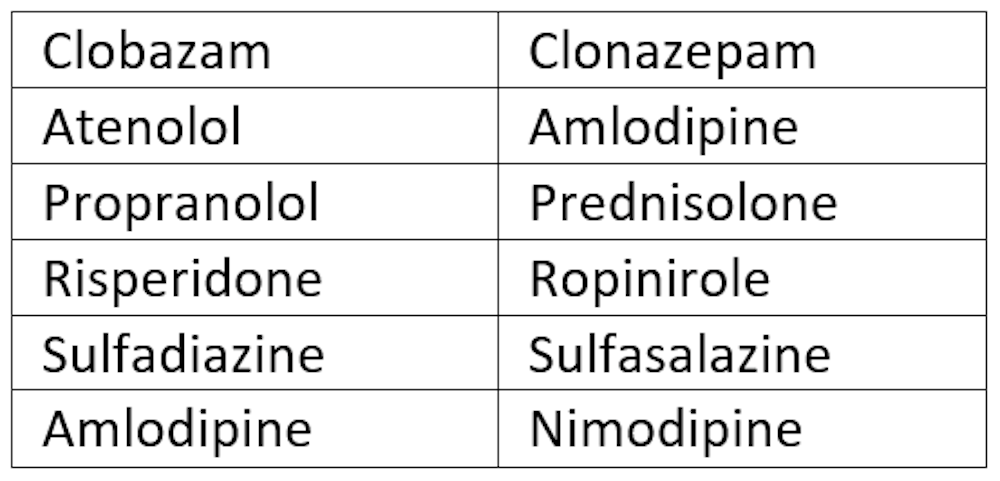
But this is avoiding the problem. Every year, hundreds of new names are created for medications, and we can reduce similarities between them before they are approved. The words that make up medication names are linguistic strings that can be analysed to identify traits which correlate with similarity. Most names involved in lookalike errors appear in reciprocal pairs, with each having been mistaken for its counterpart (as shown in the table below). This reveals inbuilt similarity, regardless of external environmental influences.
Confusing language
By looking at medication errors from a linguistics angle, we can see that once the names exist and are being used, risk is unavoidable. In one study, we looked at the guidelines used by the World Health Organisation (WHO) in creating international medication names, and the names’ linguistic features. The WHO uses a system of word parts (“stems”) to show drug class. Beta blockers such as propanolol end in -olol, for example. These stems are organised into families, and users exploit this hierarchy to recognise and remember the names. For example, omalizumab is related pharmacologically to bevacizumab and trastuzumab.
Our research team has found the guidelines to be very vague, and there is a worrying contradiction. Names that show their pharmacological grouping are usable and memorable, but they are also easily confused because they share strings of letters.
Almost half of the medication names we have analysed have an inconsistent use of pharmacological stems, such as using suffixes for some groups, and infixes or free-floating affixes in others but without signalling any rationale for the difference. For example, “vir” is used to indicate antivirals, but it sometimes appears in the middle of the name (for example, maraviroc) so it is often almost impossible for a user to identify the pharmacological group. In addition, one in every five of the medication names we looked at were only distinguishable from other names by a single letter, leaving huge potential for confusion.
We have recommended that the WHO rework their guidelines to be measurable and more simple. They are currently vague and unquantifiable, so almost impossible to follow. We have also recommended that names are measured for similarity before they are approved – but see no evidence of this being adopted to date, despite WHO recently launching a global patient safety challenge to halve major medication-related harm in the next five years.
Medication errors are a serious health care issue, but by looking at the root cause of confusion error and suggesting safer names we can hopefully reduce the prevalence of this problem.