

La première étape de l’expérience de traduction proposée dans un précédent article consiste à soumettre un échantillon poétique (le début de « Kubla Khan » de Coleridge) à Google Translate (GT) afin que l’IA le traduise en français, et de commenter le résultat. Mais avant, pour ne pas tirer de conclusions hâtives, il convient d’abord d’ouvrir la boîte noire et de comprendre, dans les grandes lignes, le fonctionnement de l’IA de GT.
Read more: Une expérience de traduction poétique : IA vs humain
Ouvrir la boîte noire : comment fonctionne GT ?
L’IA de Google Translate n’est pas comparable à l’IA ad hoc développée par DeepL pour traduire les 800 pages du livre Deep Learning en une demi-journée. Il s’agit cependant bien d’un IA qui fonctionne par traduction neuronale. De nombreuses ressources ont été fournies en ligne par des spécialistes de l’IA sur le fonctionnement de l’apprentissage profond en traduction, et sur GT en particulier (notamment cet excellent résumé). Je me contente donc de lister ici les principaux éléments en revoyant à certains de ces ressources.
-
GT emploie des réseaux neuronaux à mémoire court-terme persistante (short long-term neural networks, LSTN). Les humains ont, littéralement, de la suite dans les idées – « Our thoughts have persistence » –, c’est-à-dire que nous conservons sans nous en rendre compte une très grande quantité d’informations qui nous permettent de produire comme d’interpréter quasi-instantanément des messages linguistiques. Les LSTN ont pour but non pas de reproduire cette capacité de la cognition humaine, mais de produire des résultats analogues.
GT ne traduit pas mot à mot, comme le ferait un nouvel apprenant d’une langue en cherchant tous les mots dans le dictionnaire en en essayant de constituer pas à pas une phrase cohérente, mais séquence par séquence (abrégé en seq2seq, pour sequence to sequence). Une séquence est ici une phrase, ou parfois un syntagme (groupe grammatical fonctionnel). C’est un très net progrès : en 2003, Umberto Eco remarquait que nombre d’incohérences dans une traduction automatique reposait sur une démarche de traduction trop segmentée de la part de la machine, qui donnait l’impression de choisir les mots plus en rapport avec son dictionnaire intégré (« les synonymes d’Altavista ») qu’avec le contexte syntaxique et sémantique du texte à traduire. Le seq2eq permet à la machine de traiter, en partie, cette question du contexte.
L’algorithme BLEU (bi-lingual evaluation understudy, littéralement, une doublure pour l’évaluation bilingue) est un autre instrument de traitement contextuel. GT ne fonctionne pas en référence à une interlangue, c’est-à-dire qu’elle ne traduit pas le texte de l’original dans un langage machine unique (une forme de « langue parfaite ») qu’elle retraduirait ensuite dans la langue-cible. Au contraire, GT fonctionne par paires de langues : anglais↔chinois, anglais↔français, etc. À partir d’une comparaison statistique entre les traductions possibles que la machine « envisage » à des traductions humaines d’échantillons comparables qui sont répertoriés dans son corpus, BLEU définit la « meilleure » traduction comme celle qui ressemble le plus à une traduction humaine.
Un corpus en augmentation perpétuelle. Seq2seq comme BLEU ne sont envisageables que si l’IA peut « apprendre » en traitant un très vaste corpus. La machine, en effet, ne connaît pas la grammaire et ne partage pas l’expérience humaine que décrivent les messages linguistiques : elle produit ses résultats à partir de son corpus-témoin, vaste compilation de textes écrits par l’homme qui lui servent de référence. L’utilisateur de GT peut avoir un aperçu du corpus quand il met un mot en surbrillance dans un des champs de texte (cible ou source) :
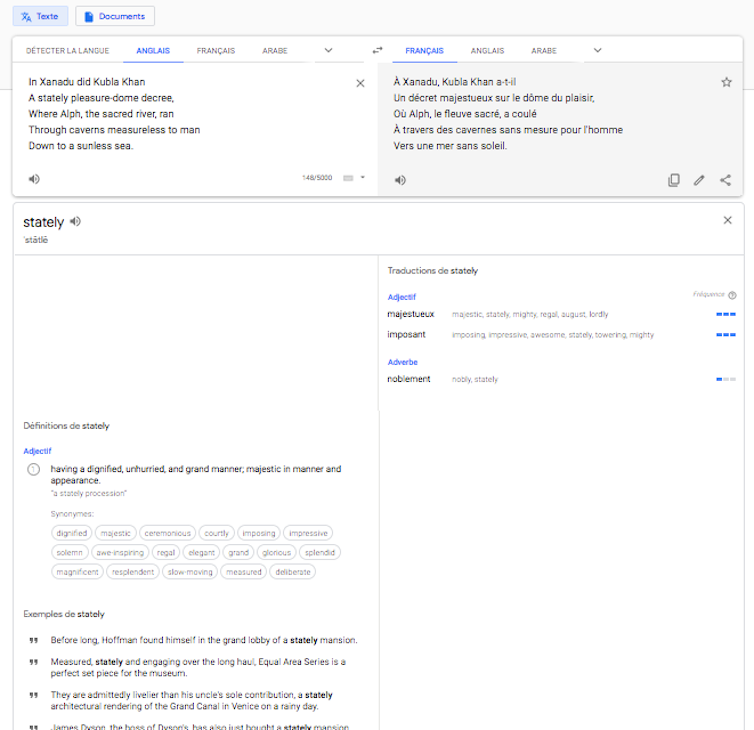
GT comporte enfin un bouton « Améliorer cette traduction ». En cliquant dessus, l’utilisateur peut intégrer au corpus sa propre traduction de la séquence sélectionnée, s’il la juge meilleure que celle proposée par l’IA. Il s’agit alors moins de traduction automatique que de traduction assistée par ordinateur, puisque l’utilisateur est explicitement appelé à exercer sa compétence translinguistique pour corriger le résultat de la machine.
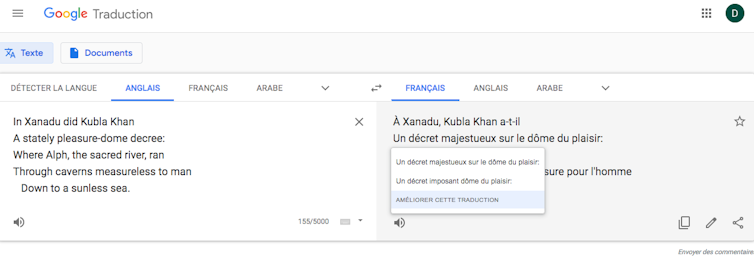
Si les utilisateurs, dans un esprit de développement collaboratif, peuvent être heureux de nourrir le corpus de GT, il convient ici de remarquer qu’en exerçant leur compétence pour aider GT à progresser ils travaillent, d’une certaine manière, gratuitement.
Quand Google Translate traduit Coleridge
Tout cela étant acquis, demandons maintenant à GT de traduire le début de « Kubla Khan ». On obtient le résultat suivant :
À Xanadu, Kubla Khan a-t-il
Un décret majestueux sur le dôme du plaisir :
Où Alph, le fleuve sacré, a coulé
À travers des cavernes sans mesure pour l’homme
Vers une mer sans soleil.
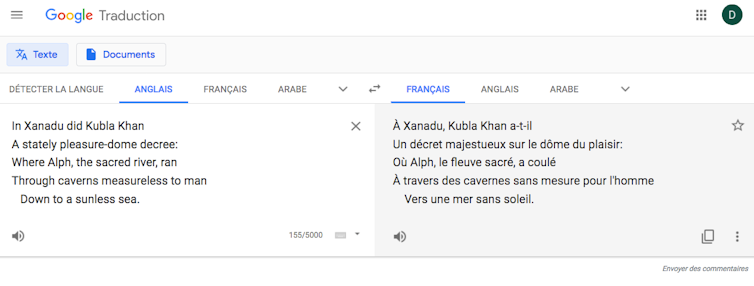
Nous avons été prévenus que l’IA n’est peut-être pas la plus à même de rendre le « style », c’est-à-dire la structure formelle qui rend ce texte mémorable. En revanche, nous attendons d’elle qu’elle restitue au moins le « contenu propositionnel » (U. Eco) du texte, c’est-à-dire la relation qu’il exprime entre des objets indépendamment de sa forme. Ce contenu propositionnel est en principe traduisible dans toutes sortes de langages, qu’ils soient naturels ou formels. Par exemple, on peut exprimer le contenu propositionnel des deux premiers vers par la paraphrase dans une langue naturelle : « Kubla Khan a fait construire un palais », ou par une relation logique dans un langage formel : D(k,p).
Si certains éléments de cette traduction sont, dans cet horizon d’attente, pleinement satisfaisants, d’autres sont davantage problématiques.
Motifs de satisfaction : v. 4-5
Rendons à GT ce qui est à GT : la traduction des vers 4 et 5 est non seulement intelligible et grammaticalement cohérente, mais exacte. On pourrait presque lui reprocher d’être trop littérale, mais c’est déjà un autre problème qui touche à la forme du message. Ayant rendu le contenu propositionnel dans un français correct, GT s’est ici parfaitement acquitté de sa tâche.
Premier problème : la traduction de ran (v. 3)
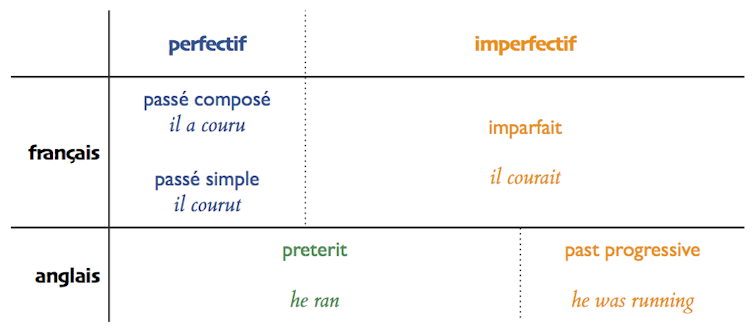
On rencontre un premier problème au v. 3, où la traduction de « ran » par « a coulé » plutôt que « coulait » ne « passe » pas très bien en français. C’est essentiellement un problème d’aspect verbal.
L’énoncé « Alph, le fleuve sacré, a coulé » présente l’action comme terminée : or Alphe n’a pas cessé de couler – au contraire, le fait qu’il passe (toujours) par ces cavernes motive le choix de Kubla. Le passé composé français montre une action accomplie, dont le terme est révolu (aspect perfectif), alors que l’imparfait montre une action dans son déroulement (comme son nom l’indique, il est d’aspect imperfectif). Chaque langue répartit différemment les valeurs aspectuelles entre ses formes verbales, et le preterit anglais peut exprimer l’un ou l’autre de ces aspects (comme son nom l’indique, c’est un passé généraliste).
GT était donc confronté ici à une alternative dans le processus de traduction (rendre le preterit par le passé composé, voire le passé simple, ou l’imparfait), et a fait « le mauvais choix ». Mais on peut même douter que l’IA ait même formulé cette alternative, dans la mesure où elle ne propose pas l’imparfait comme une traduction possible si l’on surligne le v. 3 (en vertu du seq2sq, on surligne toute la séquence, et non un seul mot) :
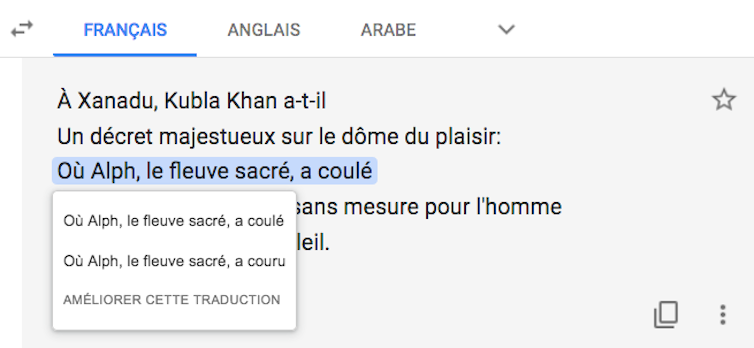
En revanche, si je soumets à GT une paraphrase prosaïque des v. 1-3 comme « Kubla had a palace built where the sacred river Alph ran », GT met spontanément la relative à l’imparfait. (Attention : il y a une petite coquille dans la capture, Kubka au lieu de Kubla.)
On admettra volontiers que ce n’est pas le plus gros problème de cette traduction. Même si la proposition de GT n’est pas acceptable comme version définitive, elle transmet tout de même le contenu propositionnel du texte, et la compétence linguistique du lecteur francophone rétablira probablement « coulait » sans trop d’hésitation, car on comprend bien, malgré tout, que le fleuve coule toujours parmi les cavernes sans lumière de Xanadu.
Deuxième problème : did + decree = decreed (v. 1-2)
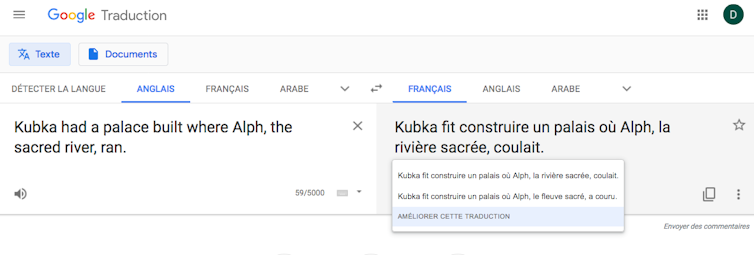
Pourquoi GT a-t-il plus de mal avec le texte original de Coleridge qu’avec une paraphrase ? Probablement parce que sa traduction des vers 1-2 est très insatisfaisante, et que l’IA n’a pas « compris » le contexte grammatical de la proposition relative où figure « ran ». La phrase des v. 1-2 en français est à la limite de l’intelligible, et présente une structure d’interrogative (avec inversion du sujet) alors qu’il s’agit dans l’original d’une phrase assertive – ce dont GT ne se rend pas compte.
En anglais, la structure « auxiliaire do conjugué + verbe lexical à l’infinitif sans to » sert effectivement à construire les interrogatives directes :
« Did Kubla build a palace in Xanadu ? » = Kubla a-t-il fait construire un palais à Xanadu ?
« Does she like green tea ? » = Aime-t-elle le thé vert ?
Mais alors la modalité interrogative est signalée par un point d’interrogation : ce n’est pas le cas dans le texte de Coleridge, et il est étonnant que GT n’ait pas analysé cela comme un indice décisif.
En anglais, la structure « auxiliaire + verbe lexical » dans une phrase assertive a une valeur emphatique. C’est une façon d’insister sur le verbe en le dédoublant : l’auxiliaire a une pure valeur grammaticale (il donne le temps verbal et la personne) qu’il faut appliquer à la valeur sémantique du verbe lexical. Ici, did + decree = decreed ≈ « décréta ». Cet emploi n’est pas exclusivement littéraire et existe dans l’usage courant :
« Kublai Khan did build a palace in Shangdu » ≈ Kubilaï Khan a bien fait construire un palais à Shangdu.
« She does write beautifully » ≈ Elle écrit vraiment très bien.
Ici, GT ne parvient pas à identifier cette construction, et donc à restituer le sens de la phrase – peut-être parce que « did » et « decree » sont séparés par six mots (soit deux syntagmes : le COD et le sujet du verbe). Du coup, l’IA traduit en français « did » par un auxiliaire de passé composé avec inversion dans le v. 1 (« a-t-il »), qu’elle laisse en suspens (pas de participe passé dans le v. 2).
Ici, GT ne se contente pas de faire abstraction de la forme du message : son IA n’en restitue pas de manière intelligible le contenu propositionnel ; c’est un problème grave qui affecte l’intelligibilité même du texte traduit.
Le recyclage syntaxique de GT : decree = décret ?
Si GT n’arrive pas à recoller la forme verbale composée, c’est probablement qu’il est induit en erreur, au v. 2, par l’homonymie entre to decree (décréter) et a decree (un décret) : l’IA interprète « decree » comme un nom, et nom comme une partie d’une forme verbale ; ce « décret » devient alors le COD de « did ».
À partir de là, GT procède à ce qu’on pourrait appeler un recyclage syntaxique : l’IA essaie de faire sens des différents groupes de la phrase et les réorganise dans une nouvelle analyse grammaticale, pour finir par proposer le segment « un décret majestueux sur le dôme de plaisir ». Dans cette analyse, « a stately pleasure-dome decree » est un grand groupe nominal, où l’article indéfini « a » et l’épithète « stately » seraient incidents à « decree », et où « pleasure-dome » serait un substantif modificateur (noun modifier) lui aussi incident à « decree ».
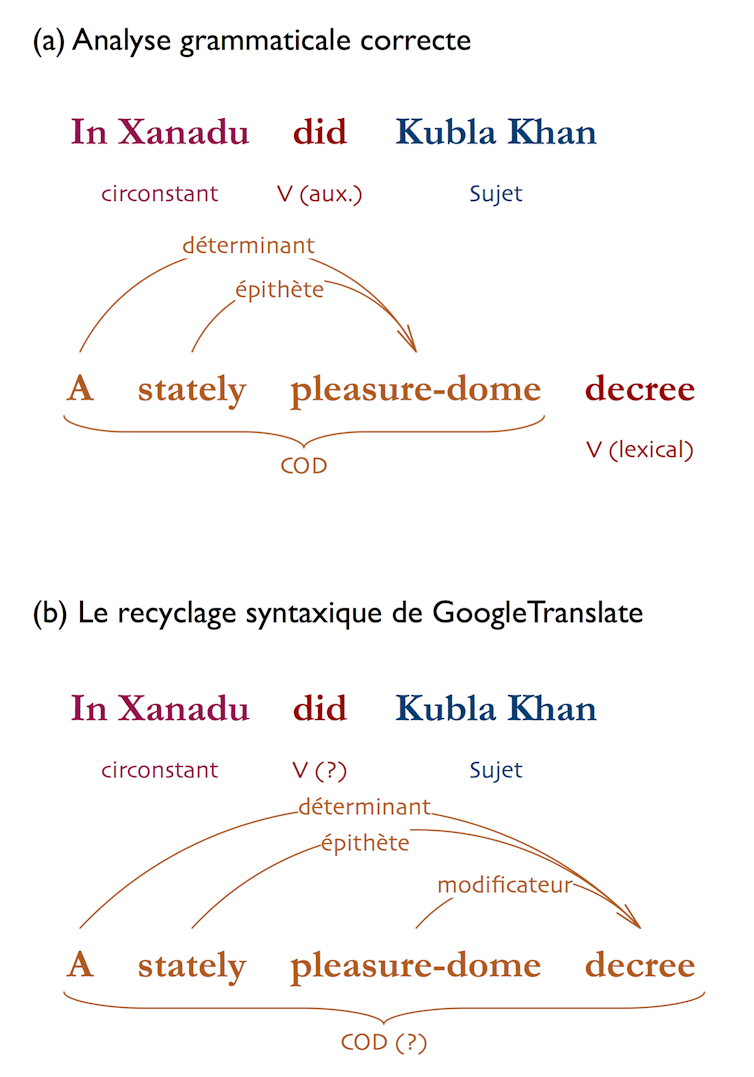
Cet exemple permet d’apprécier la puissance et les limites de GT dans l’évaluation sémantique de l’échantillon sur la base de son corpus. D’une certaine manière, GT ne s’en sort pas mal. Les modificateurs anglais expriment des relations extrêmement diverses entre les choses pour lesquelles le français a des moyens d’expression tout aussi divers :
« a dog walker » = un·e promeneu·r·se de chiens
« an immigration decree » = un décret (portant) sur l’immigration
« a hot-air balloon » = un ballon (gonflé) à (l’)air chaud [= un aérostat]
« parrot food » = de la nourriture pour perroquet
Son corpus montre à GT que les décrets sont généralement « sur » ce qui les détermine, et non « de », « à » ou « pour » ; on imagine très bien Kubla, type de l’autocrate oriental, donner un « décret sur le dôme de plaisir ». En revanche, son corpus aurait aussi dû montrer certaines autres choses à GT.
Premièrement, au niveau syntaxique, « to do a decree » passe assez mal en anglais, et sera moins souvent produit par un locuteur humain que « to make a decree », ou mieux encore « to issue/to give a decree ». Il est donc peu probable que la première expression soit davantage utilisée dans le corpus que les trois autres : statistiquement, l’analyse « did… decree » devrait l’emporter sur « did… a… decree ». (C’est le cas dans le corpus Linguee, qui sert de base à DeepL : « did a decree » n’est pas répertorié du tout, « made a decree » l’est, et la solution la plus fréquente est « issued a decree »). La faible fréquence de cette association aurait pu alerter GT : sa traduction a, statistiquement, moins de chances d’être la bonne.
Deuxièmement, au niveau sémantique, on imagine facilement un dôme majestueux (comme ceux de Milan, du Panthéon ou du Taj Mahal) ; mais que serait un « décret majestueux » ? Un parchemin enluminé, peut-être ? L’expression peine à faire sens. Ainsi, si l’apprentissage profond permet à GT de développer, par inférence statistique, l’apparence de compétences syntaxique et sémantique, celles-ci sont mises en échec par une homonymie et une construction grammaticale qui ne sont en rien réservées à la langue poétique.
Conclusion provisoire : GT sait-il traduire la poésie ?
Il y aurait encore des remarques à faire sur la traduction de GT – par exemple, sur le choix des articles dans « le dôme du plaisir » : on soulèverait alors un autre problème de sélection sémantique lié, cette fois, à l’actualisation du nom. Mais les remarques qu’on a déjà faites permettent de tirer un premier bilan.
L’IA de GT a traduit notre échantillon poétique sans rien en omettre, et une bonne moitié de cette traduction est, au moins au niveau du contenu propositionnel, très acceptable. Là où elle se trompe, l’IA fait malgré tout preuve d’une certaine agilité grammaticale pour recycler les éléments de l’original dans sa traduction. En termes de performance, elle est au niveau d’un étudiant débutant dans la traduction littéraire, et dont la pratique de la langue anglaise n’est pas encore très sûre.
Si l’on corrigeait un travail humain, on parlerait de solécisme au sujet du « a-t-il » en suspens du v. 1 : c’est une construction agrammaticale qui, ici, empêche la transmission du contenu propositionnel du texte ; ce solécisme est associé au contresens sur l’interprétation de « decree ». La question est maintenant : dans quelle mesure est-ce là « la faute » du poète, c’est-à-dire de l’emploi poétique de la langue et de ses possibilités ?
D’un côté, le lexique n’est pas vraiment problématique, et le corpus de GT, composé de textes contemporains, sait que decree peut être un verbe ou un nom ; les structures syntaxiques, si elles servent ici des choix expressifs, ne sont pas non plus rares, comme nos exemples l’ont montré. D’un autre côté, on pourrait arguer que la syntaxe de Coleridge est un peu alambiquée, et que ces contorsions linguistiques font partie du propre de la poésie (que les Français pensent à la syntaxe de ce vers de la Marseillaise : « Contre nous de la tyrannie l’étendard sanglant est levé » !)
Pourtant, la présentation versifiée du texte, première spécificité poétique, n’est pas déterminante dans ces erreurs. Si l’on soumet à GT le même échantillon déversifié, le résultat est étonnant :
« À Xanadu, Kubla Khan a fait un décret majestueux en forme de dôme de plaisir : où Alph, le fleuve sacré, traversait des cavernes incommensurables pour l’homme jusqu’à une mer sans soleil ».
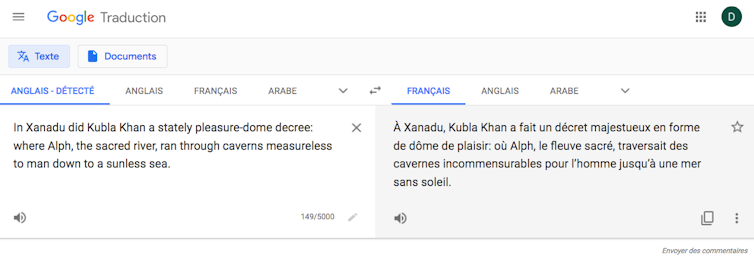
Ce qui était bon le reste (voire s’améliore : « traversait » est une traduction très acceptable de « ran through »). Le solécisme dans la traduction disparaît, puisque « did » est maintenant traduit par un verbe lexical au passé simple (ce qui ne veut pas dire que l’analyse grammaticale soit maintenant correcte), et « dôme de plaisir » est une nette amélioration. En revanche, le contresens sur « decree » aboutit à une traduction absurde de « pleasure-dome » analysé comme modificateur : qu’est-ce donc qu’un « décret en forme de dôme de plaisir » ?
Un ajustement dans la ponctuation permet d’obtenir un résultat dont les inexactitudes sont plus discrètes :
« À Xanadu, Kubla Khan a fait un décret majestueux sur le dôme du plaisir, où Alph, le fleuve sacré, traversait des cavernes incommensurables pour l’homme jusqu’à une mer sans soleil ».
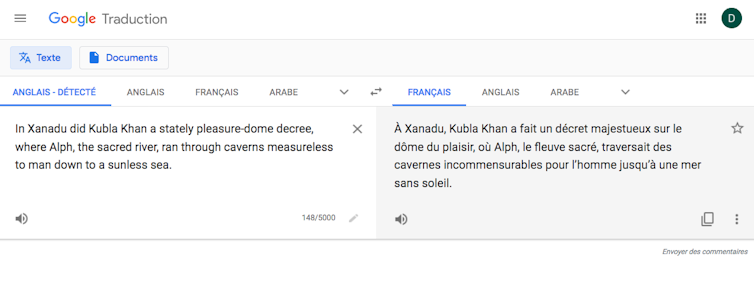
Si ces ajustements successifs sont intéressants d’un point de vue expérimental, ils tendent à montrer que GT n’est pas autonome face à la poésie : GT peut être, assurément, un assistant de traduction poétique, mais suppose un utilisateur qui ait une certaine compétence dans la langue-source, qui puisse identifier les zones problématiques et ajuster le texte soumis pour améliorer la traduction. Si l’on considère que le but de l’automatisation de la traduction poétique et littéraire n’est pas que l’IA traduise des textes aménagés pour elle, mais au contraire de généraliser l’accès au canon poétique, ce but n’est pas atteint, dans la mesure où le contrôle humain reste indispensable.
Il y aurait sans doute des façons de remédier à cette insuffisance, mais on y viendra après avoir rendu compte, dans le prochain article de notre série, de la méthode de travail du traducteur humain.