


Mais où sont donc stockées nos données ? Pas là, pas là non plus… en tous cas, pas là où nous le croyons dans la majorité des cas !
Cet article en deux parties fait suite à celui paru en février 2017 et se propose de recontextualiser le débat. La première partie a pour objet de poser la question de la localisation des données stockées, dans ce que nous nommerons de façon générique le cloud (l’informatique en nuage en français). La seconde partie a pour objet de réhabiliter les solutions basées sur un cloud de type régional, que nous caractériserons et détaillerons.
Face aux difficultés et ambiguïtés de la localisation physique des données, ce texte met aussi en perspective le cloud de type souverain et ce, malgré l’échec d’une première tentative de cloud souverain à la française (Andromède).
Ce texte se propose aussi de réhabiliter certains anciens projets, souvent raillés voire moqués, de data center (centre de données) régionaux, supportant l’offre d’un cloud régional. Enfin, cette réflexion introduit une troisième dimension à côté des clouds souverains et régionaux, celle d’un cloud soutenable.
Le cloud et ses nombreuses problématiques
Plusieurs problématiques, qui n’ont souvent rien de technologiques, se posent rapidement aux clients séduits par les solutions externalisées proposées par le cloud.
Premièrement, qui est (ou qui devient) propriétaire des données ? Deuxièmement, où sont stockées les données parmi les 4 081 data center recensés sur 118 pays ? Troisièmement, qui est responsable des données ? Quatrièmement, qui est mon interlocuteur ? Ensuite, quel est, face à lui, mon pouvoir de négociation ? Enfin, puis-je revenir en arrière (c’est la fameuse question de la réversibilité) ? Sans oublier les incontournables : combien ça coûte et comment ça marche ?
Ne pas négliger non plus d’insolentes questions telles que… quel est le PUE ? le CUE ? le WUE ? Est-ce une solution certifiée Energy Star ? Ou plus largement, quels sont les impacts environnementaux ou éthiques réels de cette externalisation ?
L’indispensable cloud souverain
Face à des failles de sécurité, de confidentialité, d’intégrité de plus en plus béantes ; face aux risques techniques, juridiques et économiques liés à l’externalisation, mais aussi face à la complexité de la question de la propriété juridique des données, le déploiement, en France, d’un cloud souverain, était devenu indispensable.
À ce propos, le « Guide sur le cloud computing et les data center à l’attention des collectivités locales » qui fut publié en juillet 2015 par le Ministère de l’Économie et des Finances introduit ainsi le cloud souverain :
« Dans le contexte d’externalisation des ressources informatiques, le concept de souveraineté des données est essentiel. Tout client, confiant ses données à un prestataire hébergeur, doit pouvoir disposer :
● d’une garantie technique, sur le niveau de sécurité offert par le prestataire et ses sous-traitants pour garantir la protection et la confidentialité des informations (dispositifs anti-intrusion, dispositifs de chiffrement…) ;
● d’une garantie juridique, sur d’une part, la non-utilisation des données par un tiers, d’autre part le non-accès aux données par un tiers en vertu de réglementations n’assurant pas une protection optimale.
Ces éléments doivent pouvoir être contractualisés et vérifiés auprès des différents fournisseurs, d’où l’importance des projets de labels et de certifications portés au niveau de l’état ».
La question de la localisation physique des données d’un cloud souverain sera abordée encore plus précisément dans le glossaire d’une note ministérielle du 5 avril 2016 :
« Cloud souverain : Modèle de déploiement dans lequel l’hébergement et l’ensemble des traitements effectués sur des données par un service de cloud sont physiquement réalisés dans les limites du territoire national par une entité de droit français et en applications des lois et normes françaises. »
L’idée principale est de doter le cloud d’un sous cloud, vers lequel pouvoir orienter les organisations publiques et parapubliques, afin qu’elles puissent tout simplement respecter leurs obligations légales et réglementaires.
De Paris à Chicago, en passant par Ningxia
Toutefois, un tel affichage volontariste ne suffit pas. Les pieds de nez à Andromède furent assez nombreux, comme en Bretagne, avec AWS. La question de la localisation physique des données reste effectivement délicate à aborder, car elle est directement liée à celle du triptyque CIA (confidentiality integrity availability, soit confidentialité intégrité disponibilité)
Notons que la solution proposée par un opérateur cloud peut être mixte et peut mobiliser plusieurs des méga data center localisés de par le monde. Il est également évident que les données puissent être sauvegardées et/ou répliquées sur plusieurs sites distants. Elles peuvent même être fragmentées et partagées entre hébergeurs.
Les données externalisées dans le cloud peuvent donc être stockées sur des sites aussi exotiques que tempérés comme Chicago (Microsoft), Maiden (Apple) Val-de-Reuil (Orange), Paris (Zayo), Marcoussis (Data4), Hohhot (China Telecom), Luxembourg (Google), Covila (Portugal Telecom) ou bien sur Montréal, Dublin, Ningxia, Francfort ou Paris (AWS).
Notons que juridiquement, des données stockées sur le territoire métropolitain peuvent théoriquement tomber sous le coup du Patriot Act américain (nouvellement Freedom Act), si l’entreprise est de nationalité américaine. C’est bien évidemment le cas des cinq GAFAM (Google, Apple, Facebook, Amazon, Apple). Notons aussi la réponse européenne, fin 2016, au travers du déploiement d’un bouclier de confidentialité avec pour feuille de route le Privacy Shield.

Techniquement, ces mégas data center proposent donc de répliquer les données dans différents centres de par le monde, à la fois pour des raisons de sécurité (si un data center « tombe » pendant quelques heures, alors un autre peut prendre la relève), et pour des raisons d’efficacité énergétique ou informatique (pour pouvoir utiliser les données proches de l’utilisateur).
Ce n’est pas le cas des micros data center, qui vont seulement dupliquer les données à quelques kilomètres, pour pouvoir affronter les plus gros aléas.
Pour un cloud régional et souverain
La question d’un cloud qui garantirait à ses clients une certaine localisation physique et géographique (par exemple une région) des données est donc fondamentale. Nous nommerons ce type de cloud un « cloud régional » et, en cohérence avec la précédente proposition, nous le définirons ainsi :
« Cloud régional : Modèle de déploiement dans lequel l’hébergement et l’ensemble des traitements effectués sur des données par un service de cloud sont physiquement réalisés dans les limites du territoire d’une des 13 régions administratives françaises. »
Certes, cette question n’est pas nouvelle. Les premiers projets de data center régionaux datent des années 2010 avec, par exemple, ceux portés par ADN’Ouest. Cette éventualité s’installe peu à peu dans le débat public, notamment pour faire face aux exigences croissantes venant des collectivités territoriales, du public et du parapublic, voire des TPE et ETI.
Toutefois, ne nous méprenons pas. Un cloud régional (garanties sur la localisation physique) n’est donc pas forcément un cloud souverain et un cloud souverain (garanties territoriales, techniques et juridiques) n’est donc pas automatiquement un cloud régional… Cependant un cloud qui serait à la fois souverain et régional est tout à fait envisageable en 2017. Il serait même opportun, selon un grand nombre d’acteurs, notamment économiques, politiques, académiques, praticiens et associatifs.
En particulier, et paradoxalement, depuis la fin officielle, il y a un an déjà, de l’expérience Andromède, pilotée par l’État français. Mais l’activité demeure fleurissante, citons simplement en ce moment en France, les performances des opérateurs OVH et Orange/Cloudwatt (malgré la polémique liée au rapprochement avec l’équipementier chinois Huawai ciblant l’international), et la belle santé du marché du cloud en métropole.
Coûts et soutenabilité du cloud
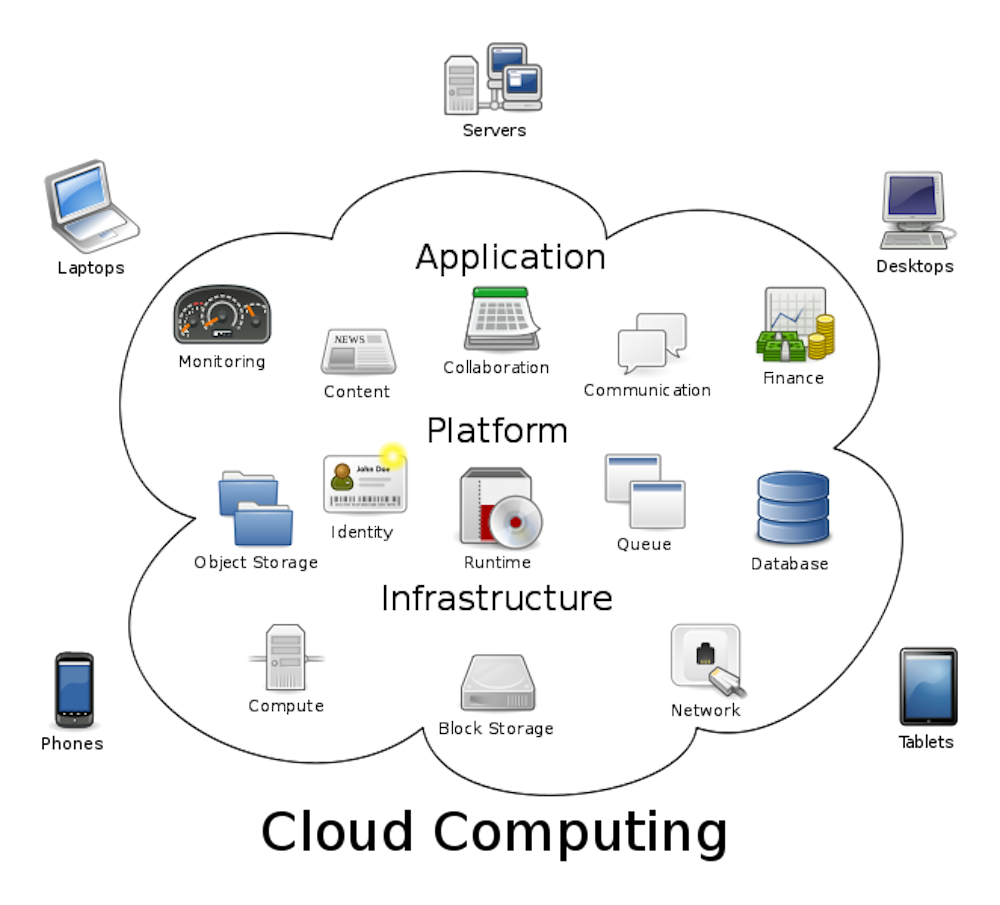
Revenons à la logique de l’externalisation des données et des applications, qui est sous-jacente à l’adoption des solutions proposées par le « cloud ». Pour faire simple, l’informatique n’est pas du tout dans les nuages… elle est, bel et bien, sur terre, et son impact environnemental est loin d’être négligeable. Les vastes usines à données des géants du cloud sont de grandes consommatrices d’énergie.
Au fond, comment expliquer cette réussite énergivore ? La diversité, la fluidité, la prévisibilité financière, la performance (affichée), la volumétrie des données à traiter, la rareté et le coût des compétences en interne, la sécurité et la simplicité (perçue) sont parmi les facteurs explicatifs majeurs de l’adoption du cloud par les clients. Nous évoquons là surtout les DSI des grands comptes, car la question se pose en termes relativement différents pour les TPE, PME et ETI.
Pour faire simple, le cloud est soit public, soit privé, soit hybride, selon que les services cloud sont partagés entre les clients, ou exclusivement réservés à un client, ou alors imbriqués. Les trois principaux modèles de services sont le « software as a service » (fourniture de logiciel en ligne), le « platform as a service » (fourniture d’une plateforme de développement d’applications en ligne), et le « Infrastructure as a Service » (mise à disposition d’infrastructures de calcul, de traitement et de stockage en ligne).
Face à la croissance de l’activité, à l’impact du cloud, et en cohérence avec les intéressantes et bienvenues innovations du Green IT, nous ajoutons donc une définition de ce que serait un cloud soutenable :
« Cloud soutenable : Modèle de déploiement dans lequel l’hébergement et l’ensemble des traitements effectués sur des données par un service de cloud sont respectueux des dimensions environnementale, économique et sociétale-éthique »
Dans la logique de ces trois définitions, le cloud privé/public/hybride peut donc être approché au travers de trois grands sous-cloud, caractérisés chacun par des critères et garanties spécifiques.

Nous allons discuter dans un second article de la pertinence et de la réalité ces trois intersections, en postulant que la cible à court et moyen terme est l’intersection verte (CSR), mais que les intersections orange et rouge seront sérieusement à prendre en considération à terme.