

Vous êtes-vous déjà demandé à quoi servaient les systèmes de détection de « robots » sur les sites web, où l’on vous demande d’identifier sur une image un passage piéton, un feu de circulation ou un animal particulier ? D’ailleurs comment le système vérifie-t-il les réponses données ? Et surtout comment ces données sont-elles utilisées ?
Cette technique a été créée dès le milieu des années 1990, le système est concrétisé et le terme inventé et déposé par des chercheurs de l’université de Canegie-Mellon aux États-Unis en 2000 dans une toute première version, avec pour objectif d’identifier des utilisateurs humains.
Puis les systèmes du type CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart/Test public de Turing entièrement automatisé pour distinguer les ordinateurs des humains) ont été démocratisés par Google en 2009. Le dispositif CAPTCHA ou reCAPTCHA (le nom du système CAPTCHA de Google) fait partie de la famille des tests de Turing. Il est une mesure de sécurité par détection d’utilisateur humain. L’objectif principal est de limiter l’accès et l’interaction de « robots » numériques, des programmes informatiques automatisés (aussi appelés « bots »), avec tout formulaire en ligne. La mesure de sécurité empêche, par exemple, les tentatives répétées de connexion à une page web, le décryptage de votre mot de passe lorsque que vous vous authentifiez en ligne, le remplissage automatisé d’un formulaire, etc.
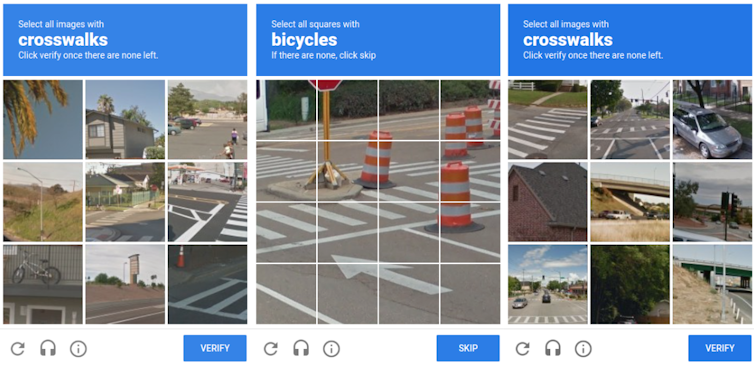
Tout d’abord sous la forme d’un texte manuscrit à retranscrire, ou encore un numéro de rue à identifier depuis une photo, les systèmes d’aujourd’hui utilisent davantage la reconnaissance visuelle d’un objet parmi un ensemble d’images ou dans une même image. Le système reCAPTCHA est proposé par Google à titre gratuit pour les gestionnaires de site web, ainsi que leurs utilisateurs.
Un intérêt pour Google
Son caractère gratuit est utile, certes. Néanmoins il sert également aux intérêts de Google. Bien que son usage comme mesure de sécurité soit indéniable, son utilisation répandue permet également de contribuer à la reconnaissance de contenus. C’est ce que l’on désigne comme l’étape de labellisation, indispensable pour alimenter des modèles d’apprentissage en IA, et notamment le Machine Learning.
Pour exemple, le système reCAPTCHA a permis dès 2011 de digitaliser l’ensemble des archives de Google Books, ainsi que 13 millions d’articles issus du catalogue du New York Times remontant à 1851. Mais dès 2017, les modèles d’apprentissage se sont montrés capables de résoudre les tests CAPTCHA initiaux basés sur des images de texte. La seconde version s’est davantage orientée vers l’utilisation d’images ou de morceaux d’images, comme l’illustre la seconde image dans cet article.
Qu’est-ce que le Machine Learning et comment cela fonctionne-t-il ?
Les modèles de Machine Learning constituent une des briques les plus utilisées aujourd’hui en intelligence artificielle. Également communément appelé apprentissage machine, cette approche permet d’entraîner un modèle, dans notre cas de reconnaissance d’image ou de texte à partir d’un jeu de données initial alimentant le modèle. À partir de ces données d’entrée, le modèle définit ainsi mathématiquement un ensemble de critères pour permettre d’estimer une probabilité de similarité. Plus le modèle dispose d’un grand volume et d’une grande variété de données en entrée, plus le modèle enrichira la définition de ces critères d’évaluation. Mais un modèle de ce type est entraîné pour reconnaître un élément spécifique (un objet, un visage, un comportement, un mouvement de fonds financier, etc.) qui est défini dès sa conception.
En apprentissage supervisé, c’est le concepteur du modèle qui définit les critères à évaluer en fournissant un ensemble de données d’entraînement préidentifiées. Cette identification préalable correspond à la labellisation des données d’entrée. Lors de son entraînement, le modèle associera ainsi les données fournies à leur labellisation spécifique pour construire une matrice de critères.
La labellisation des données d’entrée constitue donc un élément essentiel pour d’entraînement, notamment des modèles de reconnaissance visuelle.
Un enjeu de taille pour l’entraînement des modèles d’IA
Le volume et la variété des données collectées aujourd’hui sont plus que gigantesques, et cette labellisation ne peut se faire exclusivement de manière automatisée par une machine. Ainsi l’intervention d’un acteur humain est nécessaire pour traiter et labelliser l’ensemble de ces données.
C’est ce qu’il se passe lorsque vous utilisez un système du type reCAPTCHA. Celui-ci collecte ainsi les contributions de chacun pour labelliser et classifier les images proposées. La machine aura effectué un prétraitement, mais l’intervention humaine permet de confirmer cette classification initiale. Démultipliez cela par le nombre d’utilisateurs en variant les propositions d’images, et vous obtenez ainsi un système de confirmation optimisé à moindre coût. La démultiplication est nécessaire afin de garantir au maximum la véracité des données collectées. En effet, la qualité des données d’entrée pour ces modèles est essentielle, et est l’un des principaux enjeux aujourd’hui de la conception et de l’utilisation pertinente des modèles d’intelligence artificielle.
Ces labellisations contribuent ainsi l’amélioration des données d’entraînement destinées à Google Maps, au moteur de recherche d’images de Google ou encore aux modèles qui seront peut-être à terme utilisés par les véhicules autonomes (et notamment le projet Waymo de Google).
Les travailleurs du clic
Une partie de ces tâches est réalisée par les utilisateurs du web au quotidien, sans même le savoir comme nous l’avons vu précédemment. Néanmoins certaines actions sont réalisées à la chaîne par des personnes très faiblement rémunérées et à la tâche pour le faire, comme l’a révélé récemment une enquête publiée par Time Magazine sur les travailleurs nigérians, contributeurs de ChatGPT.
Ces travailleurs du clic font partie intégrante du bon fonctionnement de ces modèles d’IA. Antonio Casilli, chercheur et professeur de sociologie à Telecom Paris, a depuis longtemps travaillé sur le sujet, mettant en avant notamment cette approche et les pratiques des plates-formes numériques comme Google (Alphabet), Facebook (Meta), ou encore Amazon.
Difficile cependant de définir la part de l’un et de l’autre sur l’ensemble du système et des acteurs aujourd’hui impliqués.
Il s’avère que cette forme de microtravail rémunéré, où les contributions des utilisateurs (non rémunérées), sont indispensables pour alimenter les modèles que l’on connaît, et couvre d’ailleurs différents aspects de contribution. Comme l’explique l’article publié en 2020 par Poala Tubaro, Antonio Casilli et Marion Coville, ces contributions à la marginalisation et à la précarisation d’une partie non négligeable de travailleurs du numérique.
Des alternatives à ces systèmes
Il existe des alternatives au système reCAPTCHA, qui reste néanmoins très largement utilisé. Pour exemple, nous pouvons citer les solutions du type Puzzle CAPTCHA, ou hCAPTCHA. Néanmoins, ces alternatives demandent souvent soit une implémentation à réaliser par le gestionnaire du site web, soit une contribution financière, à comparer avec la gratuité du reCAPTCHA proposée par Google.
De son côté Google travaille également sur une nouvelle version de la solution reCAPTCHA (v3). Cette version permettrait de s’affranchir de l’interruption de navigation imposée par la v2 avec son popup, en calculant un score permettant de déterminer si le comportement observé sur un site web est davantage lié à un humain ou un bot.