
Mistakes in the paper version of the Encyclopædia Britannica took a long time to correct – years often passed between revised editions – but these days editing information is much easier. In electronic sources, like Wikipedia, anyone can log on and use simple web-based tools to make corrections or even improvements.
Human genomes also contain various errors or mutations. Many are relatively harmless but some cause life threatening genetic diseases. In a few cases, patients have been treated by conventional gene therapy; new genes have been carried in by viruses. These can then compensate for defective genes. But so far few – if any – patients have had their mutations corrected by genomic editing.
Likewise in the agricultural world, most applications of genetic engineering have involved inserting new genes, termed transgenes, rather than using editing to incorporate desirable genetic variations.
Synchronous technological revolutions
This may all change now that new editing tools have come on the scene. A quiet revolution is occurring in our ability to modify living genomes.

Most importantly the new editing tools have arrived in the midst of a second revolution – a revolution in our ability to sequence large genomes.
The affordable sequencing of human genomes has allowed the ready identification of myriad harmful mutations. Conversely, in agriculturally important organisms, new beneficial gene variants have been identified. So it is becoming more and more relevant to think about editing such variants in or out.
At the same time the improvements in sequencing also mean that one can readily re-sequence after editing. One can check whether any unintended errors have been introduced.
The big advantage of genomic editing over the addition of new genes by gene therapy or transgenesis is that a defect is corrected, or a desired variation is introduced, via a single, targeted and permanent change. Since the change already exists in nature, it should work effectively, and it should be safe.
In contrast, gene therapy has been severely hampered by the epigenetic silencing of transgenes, as well as by the unwanted insertion of new genes beside important growth control genes – that in one case led to uncontrolled cellular growth and cancer.
Tools for modifying genomes
So what are these new genomic editing tools, where did they come from, how do they work, and why are they not more widely talked about?
As often happens the new tools came from fundamental research – research into DNA-binding proteins or the mechanisms by which bacteria protect themselves from viruses. The key development is that it is now much easier to design DNA-targeting reagents that – at least in theory – can surgically cut a single gene within a complex genome.
Breaks in DNA can be lethal so the cell has in-built machinery that repairs any nick as soon as possible. One strategy is to grab any available spare DNA that seems to match the damaged DNA and to stitch it in as a replacement – just as you might darn a red pair of socks with any red wool that you find lying about in the cupboard. This is called homologous DNA repair.
Genomic editing is carried out by introducing a specific DNA-cutting module along with a piece of repair DNA, carrying the change you want to incorporate. When the original DNA gets cut, the cell replaces it with the donor DNA.
Surgically targetting chosen human genes
People have studied DNA-binding and DNA-cutting proteins for a long time and many are known. But the first generation of these, bacterial restriction enzymes, recognised very short DNA sequences.

The restriction enzyme EcoRI (that helps the bacterium E. coli protect itself from invading DNA viruses) recognises and cuts sequences of the form GAATTC (a string of DNA subunits or nucleotides and carrying in order a guanine, two adenines, two thymines and a cytosine). This sequence is only 6 units long and it occurs by chance millions of times in the human genome.
EcoRI is a useful tool when cutting and joining short pieces of DNA in the lab – pieces that only have one or two GAATTC motifs – but it is useless in terms of trying to surgically cut and repair a single human gene within our vast genome.
To get an idea of the importance of specificity, think of the Google search engine. If you typed in the word “editing” you might never find this article, but if you type in “genomic editing” you may. To be safe you could type in this whole sentence, or any other long sentence. The unique sequence of letters should be enough to take you right here.
A better toolbox
The first breakthrough in designing reagents that could target longer sequences came from the study of DNA-binding proteins in the model organism, the African clawed frog (Xenopus laevis).
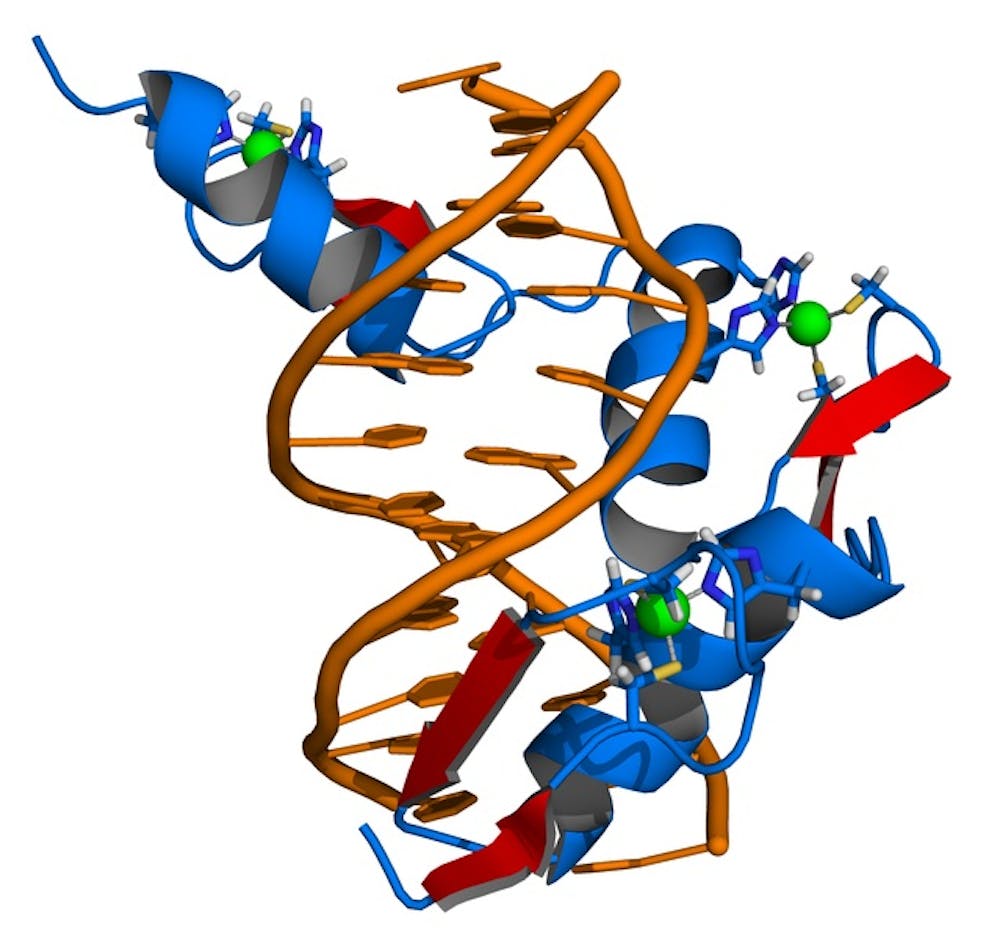
Nobel laureate Aaron Klug, who incidentally was a student with the late biophysicist Rosalind Franklin, studied a protein called Transcription Factor for polymerase III A (TFIIIA).
{kind=link}
His work showed that TFIIIA bound DNA via a series of short domains he called “zinc fingers” – because they curled around a zinc ion to form a shape that could stretch out to fit into the major groove of DNA.
He realised that each zinc finger could bind three nucleotides, and that by linking two zinc fingers together you could bind six. A protein of six zinc fingers can bind 18 base pairs, and so on. Like the long sentences mentioned above, 18-base pair sequences are sufficiently long to identify individual human genes.
These days many different artificial zinc fingers are available and can be linked together to target virtually any 18 base pair motif.
Surgical instruments
Artificial zinc finger proteins were then hooked up to DNA-cutting enzymes, or nucleases, to generate zinc finger nucleases. These have already proved effective in carrying out genomic editing – see the video below.
But they have also turned out to be more difficult than expected to make – the rational design approach did not always lead to the desired specificity in practice and a certain amount of trial and error and screening of random variants was required to achieve acceptable specificity and tightness of binding.
Consequently, a few companies, such as Sangamo Biosciences, offered a service in making zinc finger nucleases but few laboratories adopted the technology themselves.
Now things have really changed since two new DNA-binding modules have come on the scene:
1. Transcription activator-like effector nucleases (TALENs): these are based on DNA-binding proteins found naturally in bacteria that infect certain plants.
Like zinc finger proteins they are made up of repeated modules, and in this case each module binds to two bases. By linking nine domains together, scientists can make a protein that recognises 18 base pairs.
Most importantly the rules of binding have proved to be robust so that scientists can make modules to recognise any chosen doublet and these can then be stitched together. Many laboratories have eagerly adopted this technology to target their chosen genes.
2. Clustered regulatory interspaced short palindromic repeats (CRISPRs): these are similarly attractive.
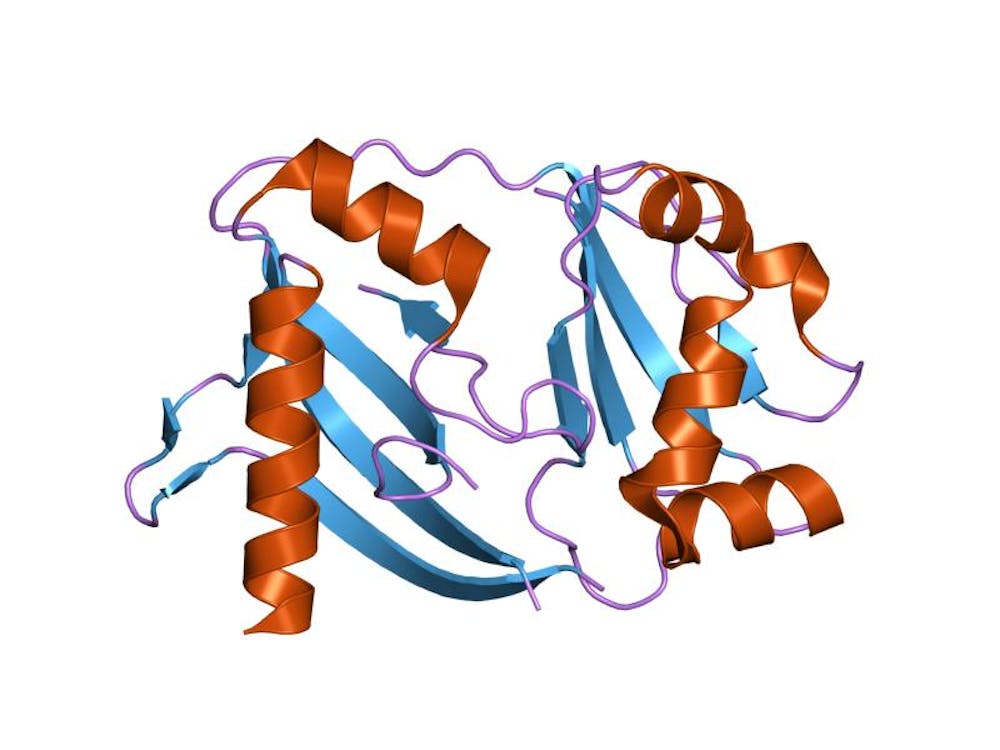
They occur naturally in bacteria and, like restriction enzymes, are involved in protecting their hosts from viruses. But unlike ZFNs and TALENs, they use a guide ribonucleic acid (RNA) to find their target genes and they team up with a bacterial nuclease, Cas9, to execute the cutting.
This use of a guide RNA is important – RNA can base pair with DNA, using the well understood rules of base pairing.
It is now a simple matter to design CRISPRs against any desired sequence and many labs have swung into action and are doing just that.
So why isn’t this revolution being talked about?
The revolution has crept up on us because the breakthrough really revolves around better and cheaper tools rather than new ideas or concepts. Homologous recombination and genomic editing was already possible in simple organisms and it was feasible but expensive to make knock-out and knock-in mice. But it was slow and laborious. Now it is easier.
The other point concerns specificity. We know we can make the desired changes but we do not know how many other unintended changes are also being introduced.
In agriculture, if the sum of all changes results in the desired outcome, other unintended changes may not matter. But before anyone embarks on human genomic editing we will want to know about any off-target effects. With the availability of affordable genomic sequencing this should be possible and it is reasonable to be optimistic that refinements in specificity and nuclease delivery will, one day, make genomic editing a useful new therapeutic tool.
We will have to think carefully, however, before encouraging everyone to dive in to be a biological Wikipedia editor at home.