

Since its public launch 10 years ago, Twitter has been used as a social networking platform among friends, an instant messaging service for smartphone users and a promotional tool for corporations and politicians.
But it’s also been an invaluable source of data for researchers and scientists – like myself – who want to study how humans feel and function within complex social systems.
By analyzing tweets, we’ve been able to observe and collect data on the social interactions of millions of people “in the wild,” outside of controlled laboratory experiments.
It’s enabled us to develop tools for monitoring the collective emotions of large populations, find the happiest places in the United States and much more.
So how, exactly, did Twitter become such a unique resource for computational social scientists? And what has it allowed us to discover?
Twitter’s biggest gift to researchers
On July 15, 2006, Twittr (as it was then known) publicly launched as a “mobile service that helps groups of friends bounce random thoughts around with SMS.” The ability to send free 140-character group texts drove many early adopters (myself included) to use the platform.
With time, the number of users exploded: from 20 million in 2009 to 200 million in 2012 and 310 million today. Rather than communicating directly with friends, users would simply tell their followers how they felt, respond to news positively or negatively, or crack jokes.
For researchers, Twitter’s biggest gift has been the provision of large quantities of open data. Twitter was one of the first major social networks to provide data samples through something called Application Programming Interfaces (APIs), which enable researchers to query Twitter for specific types of tweets (e.g., tweets that contain certain words), as well as information on users.
This led to an explosion of research projects exploiting this data. Today, a Google Scholar search for “Twitter” produces six million hits, compared with five million for “Facebook.” The difference is especially striking given that Facebook has roughly five times as many users as Twitter (and is two years older).
Twitter’s generous data policy undoubtedly led to some excellent free publicity for the company, as interesting scientific studies got picked up by the mainstream media.
Studying happiness and health
With traditional census data slow and expensive to collect, open data feeds like Twitter have the potential to provide a real-time window to see changes in large populations.
The University of Vermont’s Computational Story Lab was founded in 2006 and studies problems across applied mathematics, sociology and physics. Since 2008, the Story Lab has collected billions of tweets through Twitter’s “Gardenhose” feed, an API that streams a random sample of 10 percent of all public tweets in real time.
I spent three years at the Computational Story Lab and was lucky to be a part of many interesting studies using this data. For example, we developed a hedonometer that measures the happiness of the Twittersphere in real time. By focusing on geolocated tweets sent from smartphones, we were able to map the happiest places in the United States. Perhaps unsurprisingly, we found Hawaii to be the happiest state and wine-growing Napa the happiest city for 2013.
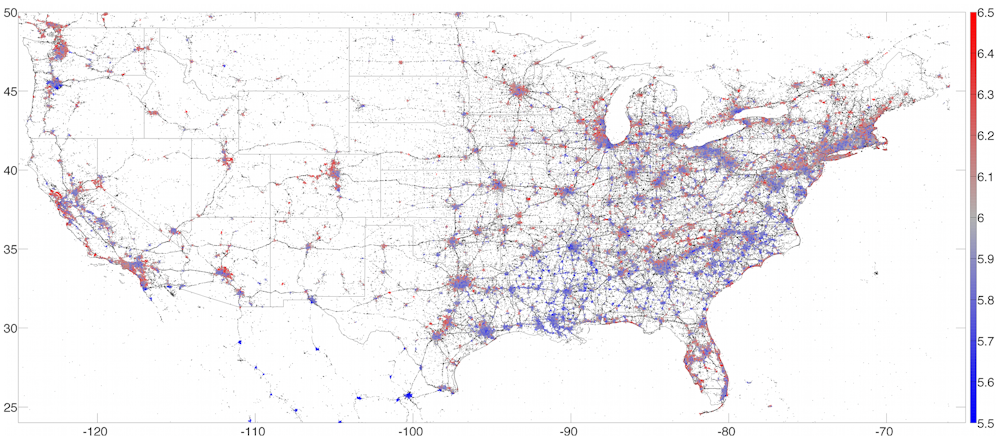
These studies had deeper applications: Correlating Twitter word usage with demographics helped us understand underlying socioeconomic patterns in cities. For example, we could link word usage with health factors like obesity, so we built a lexicocalorimeter to measure the “caloric content” of social media posts. Tweets from a particular region that mentioned high-calorie foods increased the “caloric content” of that region, while tweets that mentioned exercise activities decreased our metric. We found that this simple measure correlates with other health and well-being metrics. In other words, tweets were able to give us a snapshot, at a specific moment in time, of the overall health of a city or region.
Using the richness of Twitter data, we’ve also been able to see people’s daily movement patterns in unprecedented detail. Understanding human mobility patterns, in turn, has the capacity to transform disease modeling, opening up the new field of digital epidemiology.
For other studies, we looked into whether travelers express greater happiness on Twitter than those who stay at home (answer: they do) and if happy individuals tend to stick together in a social network (again, they do). Indeed, positivity appears to be baked into language itself, in the sense that we have more positive words than negative words. This wasn’t the case just on Twitter but across a variety of different media (e.g., books, movies and newspapers) and languages.
These studies – and thousands of others like them from around the world – were possible only thanks to Twitter.
The next 10 years
So what can we expect to learn from Twitter over the next 10 years?
Some of the most exciting work currently involves connecting social media data with mathematical models to predict population-level phenomena such as disease outbreaks. Researchers have already had some success in augmenting disease models with Twitter data to forecast influenza, notably the FluOutlook platform developed by Northeastern University and the Institute for Scientific Interchange.
Still, a number of challenges remain. Social media data suffer from a very low “signal-to-noise ratio.” In other words, the tweets that are relevant to a particular study are often drowned out by irrelevant “noise.”
Therefore, we must continuously be conscious of what’s been dubbed “big data hubris” when developing new methods and not be overconfident of our results. Connected with this should be the aim to produce interpretable “glass-box” predictions from these data (as opposed to “black-box” predictions, in which the algorithm is hidden or not clear).
Social media data are often (fairly) criticized for being a small, unrepresentative sample of the wider population. One of the major challenges for researchers is figuring out how to account for such skewed data in statistical models. While more people are using social media every year, we must continue to try to understand the biases in this data. For example, the data still tend to overrepresent younger individuals at the expense of older populations.
Only after developing better bias correction methods will researchers be able to make fully confident predictions from tweets.