
The first words anyone spoke to me once the election results came in were “What went wrong?” To which I replied, “I was tired and had trouble tying my tie. I’ll fix it before I get to class.” Far from being sartorially flippant, the point I was making was this: Nothing went “wrong.” The polls worked like they were supposed to work. If there was a problem, it was in how they were used – and the fact that we all forgot they deal in probabilities and not certainties.
Polling theory dictates the process
In political polls, like those we’ve been subjected to for the past 11 months, pollsters seek to estimate the position of those who will vote in the election. This is a notoriously difficult target to hit; until we vote, we cannot be certain if we will vote. Because the population of “people who’ve cast ballots in the 2016 presidential election” does not yet exist, pollsters must draw their sample from some other – hopefully related – population. They could choose adults, registered voters, or likely voters. None of these sampled populations are identical to the target population.

No sample can be exactly the same as the population of interest – and that difference is the source of a poll’s first structural source of uncertainty. However, methods exist to reduce structural bias by increasing the likelihood that our small sample is representative of the larger population.
The gold standard in terms of lowering bias is “simple random sampling.” In SRS, a sample is polled from the target population, wherein each person has the same probability of being selected, and the estimates reported are based solely on those polled. The beauty of a truly random sample is that it will, on average, give great estimates of the population. Its main problem is that it is heavily dependent on who winds up in the sample itself. This creates highly variable polls.
To control this variability, polling firms may use stratification – a process that attempts to weight the polls to match the demographics of the overall population. For instance, if 30 percent of voters are Republican and only 10 percent of your sample is, you’d increase the weight given to your Republicans’ responses to account for your poll having too few of them.
When done well, stratification reduces the inherent variability of poll results by exchanging some of that variability for bias. You’re swapping random error for systematic error. If your estimates of the proportion of voters who are Republican is wrong, your estimates are incorrectly weighted.
To make this concrete, simple random sampling estimates are like a pattern from a well-aimed shotgun. The average of the pattern is the center of the target, even if none of the shot actually hit it. Stratified sampling is like the pattern of a rifle: tight, but perhaps not centered on the target.

Getting the answers
A second issue arises in contacting the sample.
The 2012 election showed that relying solely on landline telephones produces estimates that tend to overestimate Republican support. On the other hand, calling cellphones is much more expensive.
Some polling organizations – including Emerson College – stayed with calling only landlines. Others called a set proportion of cellphones. Public Policy Polling stuck with calling 80 percent landline and 20 percent cellphone throughout the election cycle. Monmouth University tended closer to a 50-50 split.
Other firms gave up on the telephone altogether. Survey Monkey relied on their large database of online users. The University of Southern California created a panel of approximately 3,000 people and polled the same group online throughout the cycle.
Be assured that in the weeks ahead, polling analysts will be looking at these different methods to determine which gave estimates closest to the eventual result. We can already draw some preliminary conclusions. One is that the LA Times/USC poll, which polled the same panel of people online over time, seems to have overestimated Trump support. Their final estimates were 48.2 percent Clinton and 51.8 percent Trump (as proportion of the two-party vote). The current popular vote is split 50.1 percent Clinton to 49.9 percent Trump.
A second takeaway is that the polls from Marist University, which contacted a blend of landline and cellphone users, may have come closest at the national level. Their last estimates on November 3 had the national race at 50.6 percent Clinton and 49.4 percent Trump, as proportion of the two-party vote.
The interpretation
Once the polling firms produce their estimates, interpretation is in the hands of the various users.
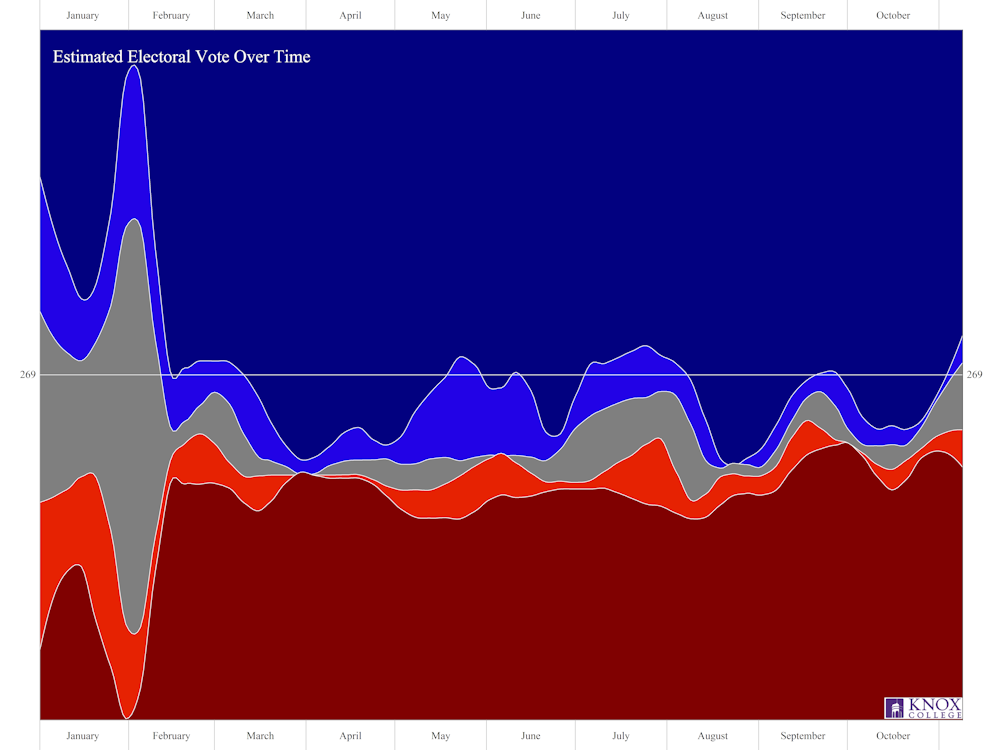
From the standpoint of researchers, the polls gave what we wanted: data from which to gauge public opinion. After an excellent 2012 season, analyst Nate Silver put his reputation on the line with some decisions he made about his estimation process: he adjusted a smoothing parameter late in the election cycle. The effect made his polls more responsive to changes in the polls. Statistically speaking, this means Silver is assuming that people are less likely to change position early in the election cycle, but may change more easily later.
Among others, the Huffington Post accused him of “putting his thumb on the scales” in favor of Trump. However, Silver made his adjustments to reflect observed human nature and action. The results support him. Where the Huffington Post had predicted a Clinton victory with 98 percent confidence, Silver’s FiveThirtyEight gave her only a 71 percent chance of winning.
Using the various polls, most major sites had the probability of a Clinton victory around 90 percent. My own model put the probability at 80 percent.
From the standpoint of the media, the polls provided a great narrative, a story to tell and motivate their readers. Most major news organizations included standard boilerplate about the polls being estimates, that they have a margin of error and that the margin of error holds 95 percent of the time.
However, in many cases, journalists didn’t seem to understand what those words meant. If the margin of error is +/- 2.5 and the support for Clinton drops 2 percent, that’s not a statistically significant change. There is no evidence that it is anything more than background noise. If the margin of error is +/- 2.5 and the support for Trump rises 3 percent, that is a statistically significant change. However, as this margin of error is measured at the 95 percent level of confidence, even those “significant changes” are wrong 5 percent of the time.
To help solve these problems, I think journalists covering elections should take a statistics course or a polling course. There is information in the numbers, and it behooves us all to understand what it does and does not say.

Finally, as with the media, the polls gave the public a great story, one that could support their views – as long as they chose the “right” polls and ignored the “wrong” ones. In 2012, many on the right claimed the polls were skewed. Once the election was over and the postmortems done, we found out they actually were, just not in the direction Republicans had claimed.
The story line of skewed polls was never rebutted in the minds of the general population. As a result, confidence in polls remains very low. It’s becoming more common for people to see polling as unethical and as a tool that advances a particular narrative.
And in fact, many polls are performed to push a political view. The push polling in South Carolina by Bush supporters in 2000 is the most notorious example of this. In the days leading up to the South Carolina primary, a group supporting George W. Bush “polled” residents, asking inflammatory questions about his opponent John McCain. The responses of those contacted were never recorded and analyzed. The sole purpose of a push poll like this is to disseminate information and influence respondents. Is it any wonder many do not trust polls?
Is polling dead?
Today, many people are talking about the death of polling. Apparently, we seem to forget that probabilities attach themselves to polling at every step in the process. The sample is a random sample from a sampled population. The target population does not exist until election day. People change their minds about voting. Everywhere in polling, there is probability.
Nate Silver’s model gave Trump a 29 percent chance of winning the presidency. My model gave him a 20 percent chance. What do those probabilities actually mean? Flip a coin twice. If it comes up heads both times, you just elected President Trump – two coin tosses in a row coming up heads has the same probability of happening that many of these polls gave for Trump moving into the White House.
And yet, polling is a science; we can always learn more. As we move forward, there are many things to learn from this election. Which polling organization was best in terms of its weighting formula? How can we best contact people? What proportion should be cellphones? How can we use online polls to get good estimates?
Those will be the questions at the forefront of polling research over the next couple years as we grapple with the causes of several recent high-profile polling “failures.”