

When Dominic Cummings made a public statement to explain why he drove 260 miles to stay with his parents during the coronavirus lockdown, the prime Minister’s chief adviser made an assertion that initially went largely unnoticed:
For years, I have warned of the dangers of pandemics. Last year I wrote about the possible threat of coronaviruses and the urgent need for planning.
It was, ultimately, beside the point but Cummings seemed to be reminding the public of his value. We are to believe that he is too vital a cog in the machine to be forced out of his job.
However, unfortunately for Cummings, it didn’t take the internet nerds long to find out his claim is not exactly true.
In fact, a quick search and check on the Wayback Machine shows only one mention of coronavirus on Cummings’ blog or any other media attached to his name. That mention is in a paragraph that was added to a blog post some time between April 11 and April 15 2020 – several months into the current crisis, when anyone could see coronaviruses were a problem, with or without an eye test. The post was originally released on March 4 2019.
How do we know the lines were added later? And why can’t we tell when exactly the paragraph is added? Let me explain.
In the last years of the 1980s, Tim Berners-Lee invented the World Wide Web (WWW) as he was frustrated with how hard it was to find different documents on different computers. His original proposal was a protocol which connects documents regardless of which computer they are stored on and allows readers to navigate between those “hypertext” documents. The first phase of development of the web was supposed to be “read-only”. However, the very first web browser that Berners-Lee released was already a web editor too. Considering the digital nature of the web documents, it would have been stupid to deal with them as “static” objects such those printed on paper.
The web was born as an intrinsically dynamic concept. The network of documents can grow and change and the documents can too.
However, two problems soon appeared. These documents need to be stored somewhere and for many reasons (including scarcity of storage in 1990s) some documents might get deleted. Ironically, the very first webpage ever created seems to have been lost, or at best is sitting on an optical drive somewhere, according to some claims.
The other issue was the need to have access to archives of previous versions of webpages after they’d been changed – say, for legal reasons.
Building an archive
To solve these two problems, ideas of regularly archiving the content of the web started to form in the mid 1990s. In 1996 “The Internet Archive” – an American “digital library” – started to “crawl” the web and make copies of the pages.
There are various other web archivers out there, too, but the Internet Archive arguably has the most comprehensive collection.
The core element of a web archiver is its web crawler – a piece of software that navigates via hyperlinks to visit web pages and copies their content. The Internet Archive has made hundreds of billions copies of most of the pages and made the collection publicly available on its service called the Wayback Machine.
Many of the pages on the web do not change much but some change very frequently and many are frankly not important enough to archive. So the archive does not have the whole history of all the webpages, but it has a good number.
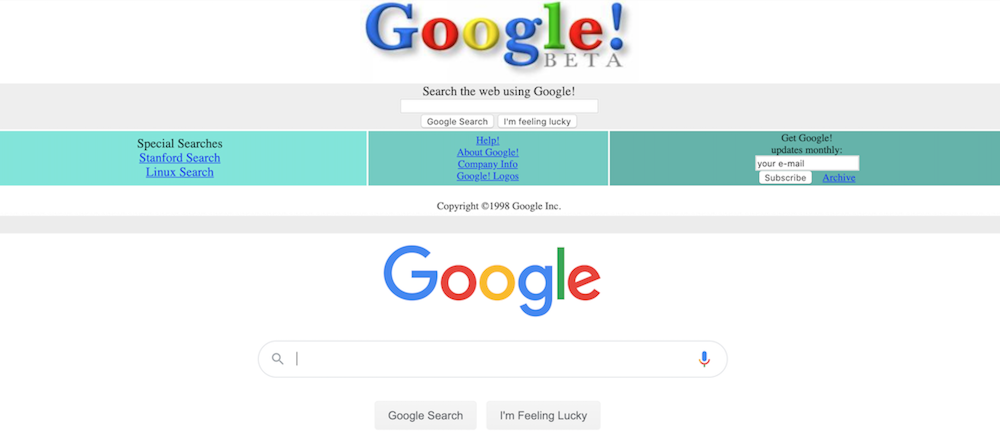
The Internet Archive crawler tries to visit “more important” and “more dynamic” pages more often. For example, Google.com was archived more than 5 million times between November 11 1998 and May 27 2020 – on average around 700 times per day. My university profile page, by contrast, has only been archived 48 times over the past seven years. I might point out that when you compare the 1998 version of the Google frontpage to today’s, there is little change to see. My page has been updated and changed many times. But the number of times that crawlers visit a page are much more influenced by the “importance” of the pages instead of how quickly it changes.
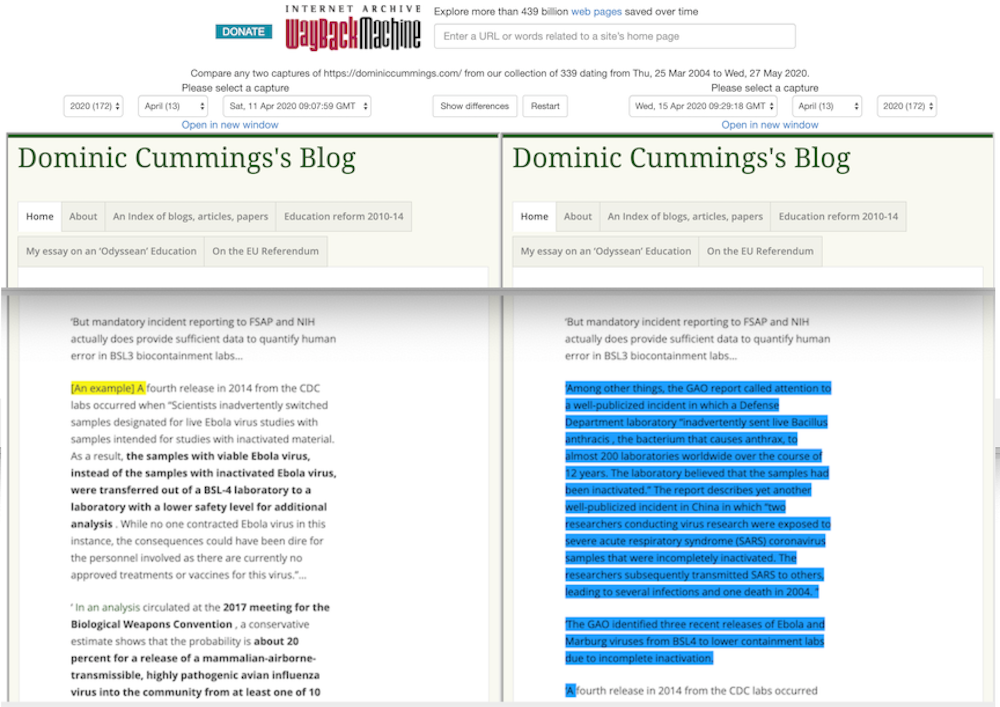
From the archive we can see that Cummings has been running his blog since 2013 and the first actual post was released in March 2014 – although someone apparently had the domain name since 2004.
There are some 330 versions of his blog saved on the Internet Archive, with many more snapshots taken in recent dates. The earliest one is dated June 29 2017. And, sure enough, as mentioned above, there were two snapshots taken on April 11 and 15. A close comparison of the two shows that the “blue” paragraph in the figure above was added in between these two dates.
Should Cummings’ blog have been more frequently visited by the Archive crawler, we could have determined the exact timing of the change even more precisely. But we at least know that it happened some time during April 2020.
For future reference, you can make the Wayback Machine make a copy of a page if it has no records of the page and you think it should. Archiving is something I’m sure Cummings will think about next time. Remember, the internet never forgets.