
We take science seriously at The Conversation and we work hard at reporting it accurately. This series of five posts is adapted from an internal presentation on how to understand and edit science by Australian Science & Technology Editor, Tim Dean. We thought you would also find it useful.
One of the most common approaches to conducting science is called “significance testing” (sometimes called “hypothesis testing”, but that can lead to confusion for convoluted historical reasons). It’s not used in all the sciences, but is particularly common in fields like biology, medicine, psychology and the physical sciences.
It’s popular, but it’s not without its flaws, such as allowing careless or dishonest researchers to abuse it to yield dubious yet compelling results.
It can also be rather confusing, not least because of the role played by the dreaded null-hypothesis. It’s a bugbear of many a science undergraduate, and possibly one of the most misunderstood concepts in scientific methodology.
The null-hypothesis is just a baseline hypothesis that typically says there’s nothing interesting going on, and the causal relationship underpinning the scientist’s hypothesis doesn’t hold.
It’s like a default position of scepticism about the scientist’s hypothesis. Or like assuming a defendant is innocent until proven guilty.
Now, as the scientist performs their experiment, they compare their results with what the’d expect to see if the null-hypothesis were true. What they’re looking for, though, is evidence that the null-hypothesis is actually false.
An example might help.
Let’s say you want to test whether a coin is biased towards heads. Your hypothesis, referred to as the alternate hypothesis (or H₁), that you want to test is that it is biased. The null-hypothesis (H₀) is that it’s unbiased.
We already know from repeated tests that if you flip a fair coin 100 times, you’d expect it come up heads around 50 times (but it won’t always come up heads precisely 50 times). So if the scientist flips the coin 100 times and it comes up heads 55 times, it’s pretty likely to be a fair coin. But if it comes up heads 70 times, it starts to look fishy.
But how can they tell 70 heads is not just the result of chance? It’s certainly possible for a fair coin to come up heads 70 times. It’s just very unlikely. And the scientist can use statistics to determine how unlikely it is.
If they flip a fair coin 100 times, there’s a 13.6% chance that it’ll come up heads 55 or more times. That’s unlikely, but not enough to be confident the coin is biased.
But there’s only a 0.1% chance that it’ll come up heads 70 or more times. Now the coin is looking decidedly dodgy.
The probability of seeing this particular result is referred to as the “p-value”, expressed in decimal rather than percentage terms, so 13.6% is 0.136 and 0.01% chance is 0.0001.
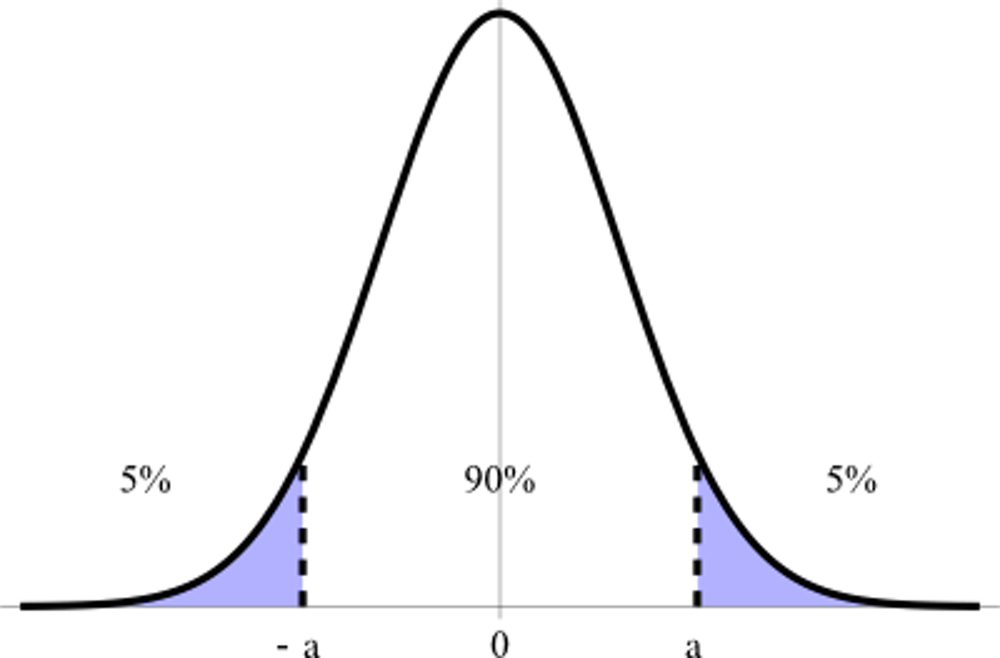
Typically, scientists consider a p-value of 0.05 to be a good indication you can reject the null-hypothesis (eg, that the coin is unbiased) and be more confident that your alternative hypothesis (that the coin is biased) is true.
This value of 0.05 is called the “significance level”. So if a result has a p-value that is above the significance level, then the result is considered “significant”.
It’s important to note that this refers to the technical sense of “statistical significance” rather than the more qualitative vernacular sense of “significant”, as in my “significant other” (although statisticians’ partners may differ in this interpretation).
This approach to science is also not without fault.
For one, if you set your significance level at 0.05, and you run the same experiment 20 times, then you’d expect one of those experiments to yield a false result, yet still clear the significance bar. So in a journal with 20 papers, you can also expect roughly one to be wrong.
This is one of the factors contributing to the so-called “replication crisis” in science, particularly in medicine and psychology.
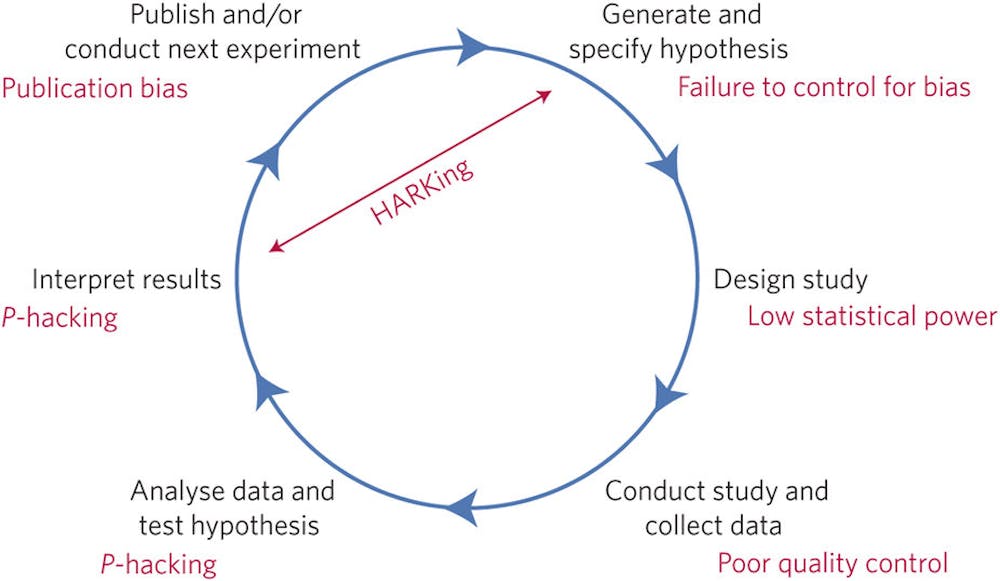
p-hacking
One prime suspect in the replication crisis is the problem of “p-hacking”.
A good experiment will clearly define the null and the alternate hypothesis before handing out the drugs and placebos. But many experiments collect more than just one dimension of data. A trial for a headache drug might also keep an eye on side-effects, weight gain, mood, or any other variable the scientists can observe and measure.
And if one of these secondary factors shows a “significant” effect – like the group who took the headache drug also lost a lot of weight – it might be tempting to shift focus onto that effect. After all, you never know when you’ll come across the next Viagra.
However, if you simply track 20 variables in a study, you’d expect one of them to pass the significance threshold. Simply picking that variable, and writing up the study as if that was the focus all along is dodgy science.
It’s why we sometimes hear stuff that’s too good to be true, like that chocolate can help you lose weight (although that study turned out to be a cheeky attempt to show how easy it is for a scientist to get away with blatant p-hacking).
Publishing
Once scientists have conducted their experiment and found some interesting results, they move on to publishing them.
Science is somewhat unique in that the norm is towards full transparency, where scientists effectively give away their discoveries to the rest of the scientific community and society at large.
This is not only out of a magnanimous spirit, but because it also turns out to be a highly effective way of scrutinising scientific discoveries, and helping others to build upon them.
The way this works is typically by publishing in a peer-review journal.
It starts with the scientist preparing their findings according to the accepted conventions, such as providing an abstract, which is an overview of their discovery, and outlining the method they used in detail, describing their raw results and only then providing their interpretation of those results. They also cite other relevant research – a precursor to hyperlinks.
They then send this “paper” to a scientific journal. Some journals are more desirable than others, i.e. they have a “high impact”. The top tier, such as Nature, Science, The Lancet and PNAS, are popular, so they receive many high quality papers and accept only the best (or, if you’re a bit cynical, the most flashy). Other journals are highly specialist, and may be desirable because they’re held in high esteem by a very specific audience.
If the journal rejects the paper, the scientists move on to the next most desirable journal, and keep at it until it’s accepted or remains unpublished.
These journals employ a peer review process, where the paper is typically anonymised and sent out to a number of experts in the field. These experts then review the paper, looking for potential problems with the methods, inconsistencies in reporting or interpretation, and whether they’ve explained things clearly enough such that another lab could reproduce the results if they wanted to.
The paper might bounce back and forth between the peer reviewers and authors until it’s at a point where it’s ready to publish. This process can take as little as a few weeks, but in some cases it can take months or even years.
Journals don’t always get things right, though. Sometimes a paper will slip through with shoddy method or even downright fraud. A useful site for keeping tabs on dodgy journals and researchers is Retraction Watch.
Open Access
A new trend in scientific publishing is Open Access. While traditional journals don’t charge to accept papers, or pay scientists if they do publish their paper, they do charge fees (often exorbitant ones) to university libraries to subscribe to the journal.
What this means is a huge percentage of scientific research – often funded by taxpayers – is walled off so non-academics can’t access it.
The Open Access movement takes a different approach. Open Access journals release all their published research free of charge to readers, but they often recoup their costs by charging scientists to publish their work.
Many Open Access journals are well respected, and are gaining in prestige in academia, but the business model also creates a moral hazard, and incentives for journals to publish any old claptrap in order to make a buck. This has led to an entire industry of predatory journals.
Librarian Jeffery Beall used to maintain a list of “potential, possible, or probable” predatory publishers, which was the go-to for checking if a journal is legit. However, in early 2017 Beall took the list offline for reasons yet to be made clear. The list is mirrored, but every month that goes by makes it less and less reliable.
Many scientists also publish their research on pre-press servers, the most popular being arXiv (pronounced “archive”). These are clearing houses for papers that haven’t yet been peer-reviewed or accepted by a journal. But they do offer scientists a chance to share their early results and get feedback and criticism before they finalise their paper to submit to a journal.
It’s often tempting to get the jump on the rest of the media by reporting on a paper published on a pre-press site, especially if it has an exciting finding. However, journalists should exercise caution, as these papers haven’t been through the peer-review process, so it’s harder to judge their quality. Some wild and hyperbolic claims also make it to pre-press outlets. So if a journalist is tempted by one, they should run it past a trusted expert first.
The next post in this series will deal with more practical considerations about about to pick a good science story, and how to cite sources properly.