


Comment réagiriez-vous si ChatGPT dévoilait votre numéro de téléphone et votre adresse privée ?
Parmi les données présentes sur le Web sur lesquelles le modèle de langage derrière ChatGPT s’entraîne, certaines informations sont personnelles et ne sont pas censées être révélées. Pourtant, ce risque est bien réel, comme l’a démontré une équipe de chercheurs, en poussant ChatGPT à révéler une grande quantité de données personnelles à partir d’une simple requête.
Pour garantir la confidentialité des données qui servent à entraîner les systèmes d’intelligence artificielle, une piste est d’utiliser des « données synthétiques » : des données fictives générées artificiellement qui conservent des propriétés statistiques du jeu de données réelles qu’elles cherchent à imiter et remplacer.
Avec des données synthétiques, on peut entraîner un système de classification ou un agent conversationnel comme ChatGPT, tester des logiciels, ou partager les données sans souci de confidentialité : des données synthétiques reproduisent par exemple les données du système national de données de santé.
Certaines des entreprises présentes sur le marché de la génération de données synthétiques, ainsi qu’une partie de la littérature académique, avancent même qu’il s’agit de données réellement anonymes. Ce terme est fort, car il sous-entend qu’on ne peut pas remonter aux données réelles – et donc, à votre numéro de sécurité sociale ou de téléphone.
En réalité, la synthèse de données possède des faiblesses et les garanties mises en avant font encore l’objet d’études.
Pourquoi tant d’engouement pour les données synthétiques ?
La synthèse de données permettrait de publier des données représentatives des données réelles d’origine mais non identifiables.
Par exemple, des données de recensement de la population peuvent être extrêmement utiles à des fins de statistiques… mais elles rassemblent des informations sur les individus qui permettent leur réidentification : leur publication en l’état n’est donc pas permise par le RGPD (Règlement général sur la protection des données).
Dans le cas de données personnelles ou de données soumises à propriété intellectuelle, ce procédé permettrait aussi de s’affranchir du cadre réglementaire qui limite souvent leur publication ou leur utilisation.
Il permettrait également de réaliser des expérimentations qui auraient demandé de coûteuses collectes de données, par exemple pour entraîner des voitures autonomes à éviter les collisions.
Enfin, les données synthétiques ne nécessitent pas de nettoyage des données. Cet atout est particulièrement important pour l’entraînement de modèles d’IA, où la qualité de l’annotation des données a un impact sur les performances du modèle.
Pour ces raisons, fin 2022, le marché mondial de la génération de données synthétiques avait déjà généré 163,8 millions de dollars et devrait connaître une croissance de 35 % de 2023 à 2030. L’adoption pourrait être rapide et massive, et représenter selon certaines études jusqu’à 60 % des données utilisées pour l’entraînement des systèmes d’IA en 2024.
La confidentialité est l’un des objectifs de la génération de données synthétiques, mais ce n’est pas le seul. Les acteurs du domaine entendent également profiter de l’exhaustivité des données synthétiques – qui peuvent être générées en quantité quasi illimitée et reproduire toutes les simulations envisagées, mais aussi permettre d’avoir des données sur des cas particulièrement difficiles avec des données réelles (comme la détection d’armes sur une image, ou une simulation de trafic routier avec des conditions bien particulières).
Comment génère-t-on des données synthétiques ?
Imaginons que nous voulons générer des données synthétiques comme l’âge et le salaire d’une population. On modélise d’abord la relation entre ces deux variables, puis on exploite cette relation pour créer artificiellement des données satisfaisant les propriétés statistiques des données d’origine.
Si la synthèse de données était initialement basée sur des méthodes statistiques, les techniques sont aujourd’hui plus élaborées, afin de synthétiser des données tabulaires ou temporelles – voire, grâce à des IA génératives, des données de type texte, images, voix et vidéos.
De fait, les techniques utilisées pour synthétiser des données à des buts de confidentialité sont très similaires à celles utilisées par les IA génératives comme ChatGPT pour le texte, ou StableDiffusion pour les images. En revanche, une contrainte supplémentaire liée à la reproduction de la distribution statistique des données source est imposée aux outils afin d’assurer la confidentialité.
Par exemple, les réseaux antagonistes génératifs (ou GANs pour generative adversarial networks) peuvent être utilisés pour créer des deepfakes.
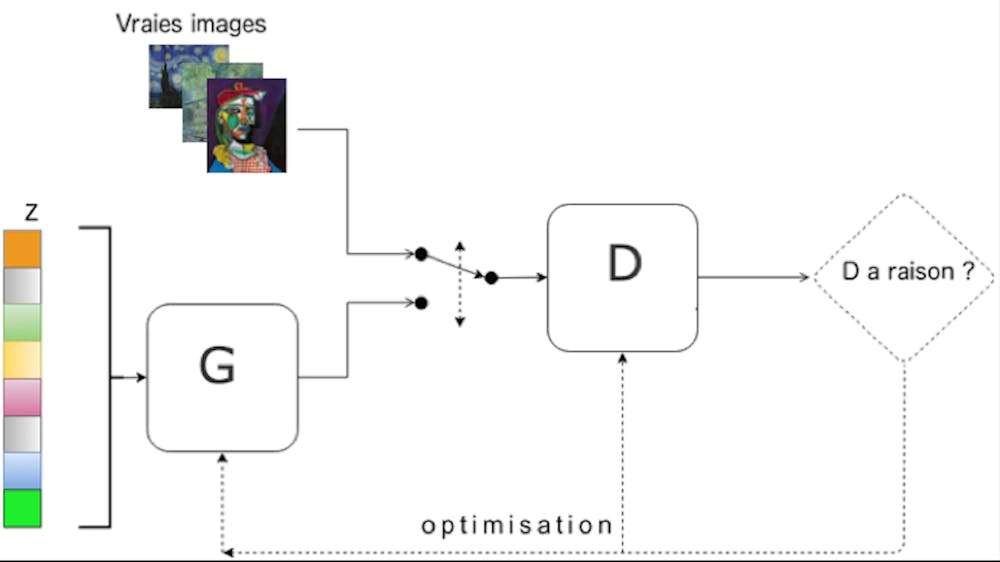
Read more: Peut-on détecter automatiquement les deepfakes ?
De leur côté, les auto-encoders variationnels (ou VAEs), compressent les données d’origine dans un espace de dimension inférieure et tentent de modéliser la distribution de ces données dans cet espace. Des points aléatoires sont ensuite tirés dans cette distribution et décompressés afin de créer de nouvelles données fidèles aux données d’origine.
Il existe d’autres méthodes de génération. Le choix de la méthode dépend des données sources à imiter et de leur complexité.
Données réelles vs données synthétiques : trouver les différences
La modélisation des données d’origine, sur laquelle repose le procédé de synthèse, peut être imparfaite, erronée ou incomplète. Dans ce cas, les données de synthèse ne reproduiront que partiellement les informations d’origine : on parle d’une « perte d’utilité ».
Au-delà d’une perte en performance, un générateur de données mal entraîné ou biaisé peut aussi avoir un impact sur des groupes minoritaires, sous représentés dans l’ensemble de données d’entraînement, et par conséquent moins bien assimilés par le modèle.
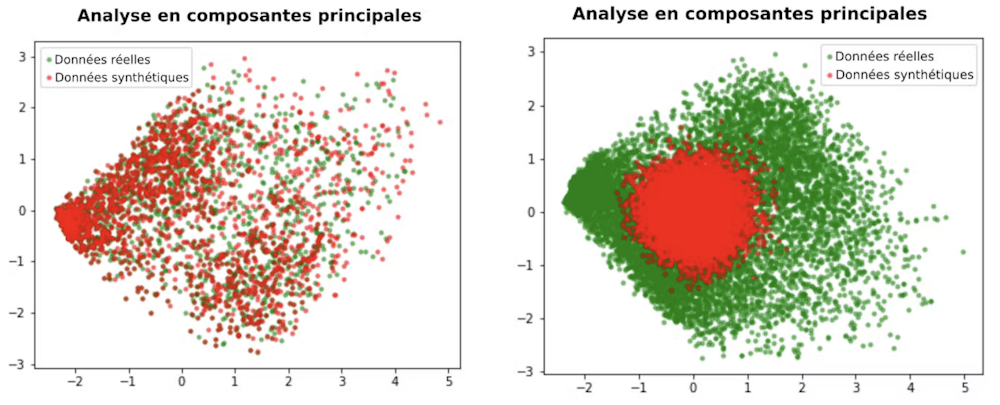
La perte en utilité est un risque d’autant plus inquiétant que seul l’organisme à la source de la synthèse est en mesure de l’estimer, laissant les utilisateurs des données dans l’illusion que les données correspondent à leurs attentes.
Données synthétiques vs données anonymes : quelle garantie en termes de confidentialité ?
Lorsque le partage de données personnelles n’est pas permis, des données personnelles doivent être anonymisées avant d’être partagées. Toutefois l’anonymisation est souvent difficile techniquement, voire même impossible pour certains jeux de données.
Les données synthétiques se placent alors en remplacement des données anonymisées. Cependant, comme pour les données anonymisées, le risque zéro n’existe pas.
Bien que l’ensemble des données sources ne soit jamais révélé, les données de synthèse, et parfois le modèle de génération utilisé, peuvent être rendus accessibles et ainsi constituer de nouvelles possibilités d’attaques.
Pour quantifier les risques liés à l’utilisation des données synthétiques, les propriétés de confidentialité sont évaluées de différentes façons :
Possibilité de lier les données synthétiques aux données d’origine
Divulgation d’attributs : quand l’accès aux données synthétiques permet à un attaquant d’inférer de nouvelles informations privées sur un individu spécifique, par exemple la valeur d’un attribut particulier comme la race, l’âge, le revenu, etc.
Inférence d’appartenance : par exemple, si un adversaire découvre que les données d’un individu ont été utilisées pour l’entraînement d’un modèle qui prédit le risque de récidive de cancer, il peut en tirer des informations sur la santé de cet individu.
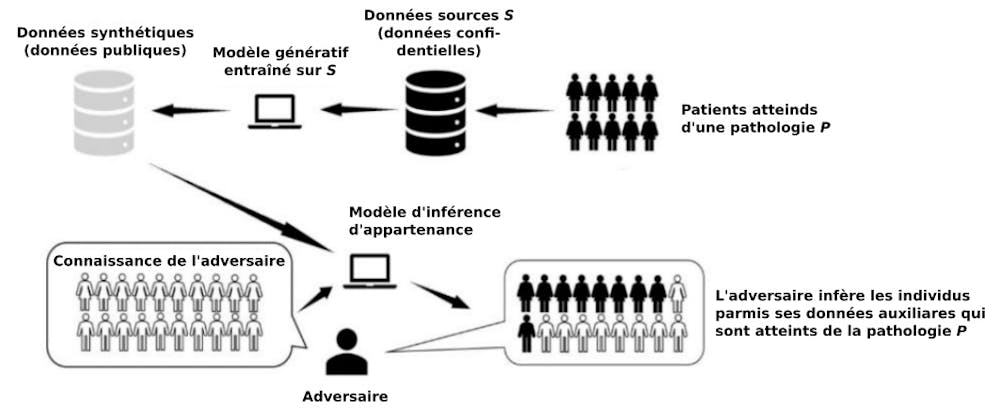
Des risques non nuls
Il est important de comprendre que dans la plupart des cas, le risque de fuite d’information n’est pas binaire : la confidentialité n’est ni totale ni nulle.
Le risque est évalué au travers des distributions de probabilité en fonction des hypothèses, des données et des menaces considérées. Certaines études ont montré que les données synthétiques offrent peu de protection supplémentaire par rapport aux techniques d’anonymisation. De plus, le compromis entre confidentialité des données d’origine et utilité des données synthétiques est difficile à prévoir.
Certaines mesures techniques permettent de renforcer la confidentialité et de réduire les risques de réidentification. La confidentialité différentielle notamment est une solution prometteuse, encore à l’étude afin de fournir des garanties suffisantes en termes d’utilité des données, de coût computationnel et d’absence de biais.
Il faut tout de même noter que si les risques liés à l’utilisation de données de synthèse ne sont pas nuls, leur utilisation peut s’avérer avantageuse pour certains scénarios d’utilisation. Par exemple, on peut calibrer la génération pour qu’elle conserve uniquement certaines propriétés des données sources pour limiter les risques.
Comme pour n’importe quelle solution de protection à mettre en place, il est toujours nécessaire de faire une analyse de risques pour objectiver ses choix. Et bien sûr, la génération de données synthétiques soulève aussi des enjeux éthiques lorsque la génération des données a comme finalité de construire de fausses informations.

Le PEPR Cybersécurité et son projet IPoP (ANR-22-PECY-0002) sont soutenus par l’Agence nationale de la recherche (ANR), qui finance en France la recherche sur projets. Elle a pour mission de soutenir et de promouvoir le développement de recherches fondamentales et finalisées dans toutes les disciplines, et de renforcer le dialogue entre science et société. Pour en savoir plus, consultez le site de l’ANR.