

Connaissez-vous les grands modèles de langage (LLM pour « large language models » en anglais) ? Même si cette expression vous semble obscure, il y a fort à parier que vous avez déjà entendu parler du plus célèbre d’entre eux : ChatGPT, de la société californienne OpenAI.
Le déploiement de tels modèles d’intelligence artificielle (IA) pourrait avoir des conséquences difficiles à appréhender. En effet, il est compliqué de prévoir précisément comment vont se comporter les LLM, dont la complexité est comparable à celle du cerveau humain. Un certain nombre de leurs capacités ont ainsi été découvertes au fil de leur utilisation plutôt que prévus au moment de leur conception.
Pour comprendre ces « comportements émergents », de nouvelles investigations doivent être menées. Dans cette optique, au sein de mon équipe de recherche, nous avons utilisé des outils de psychologie cognitive traditionnellement utilisés pour étudier la rationalité chez l’être humain afin d’analyser le raisonnement de différents LLM, parmi lesquels ChatGPT.
Nos travaux ont permis de mettre en évidence l’existence d’erreurs de raisonnements chez ces intelligences artificielles. Explications.
Que sont les « large language models » ?
Les modèles de langage sont des modèles d’intelligence artificielle qui sont capables de comprendre et de générer du langage humain. Schématiquement parlant, les modèles de langage sont capables de prédire, en fonction du contexte, les mots qui ont la plus grande probabilité de figurer dans une phrase.
Les LLM sont des algorithmes à réseaux de neurones artificiels. Inspirés par le fonctionnement des réseaux de neurones biologiques qui composent le cerveau humain, les nœuds d’un réseau de plusieurs neurones artificiels reçoivent généralement plusieurs valeurs d’information en entrée et génèrent ensuite, après traitement, une valeur de sortie.
Les LLM se distinguent des algorithmes à réseaux de neurones artificiels « classiques » qui composent les modèles de langage par le fait d’être basés sur une architecture spécifique, d’être entraînés sur d’énormes bases de données, et d’avoir une taille généralement gargantuesque (de l’ordre de plusieurs milliards de « neurones »).
Du fait de leur taille et de leur structure (mais aussi de la façon dont ils sont entraînés), les LLMs ont montré dès le début de leur utilisation des performances impressionnantes dans les tâches qui leur étaient propres, qu’il s’agisse de création de texte, de traduction, ou de correction.
Mais ce n’est pas tout : les LLM ont aussi fait montre de performances relativement surprenantes dans toute une variété de tâches diverses et variées, allant des mathématiques à des formes basiques de raisonnement.
Autrement dit, les LLMs ont rapidement manifesté des capacités qui n’étaient pas forcément explicitement prévisibles de par leur programmation. Qui plus est, ils semblent être capables d’apprendre à accomplir de nouvelles tâches à partir de très peu d’exemples.
Ces capacités ont créé pour la première fois une situation particulière dans le domaine de l’intelligence artificielle : nous disposons désormais de systèmes tellement complexes que nous ne pouvons pas prévoir à l’avance l’étendue de leurs capacités. En quelque sorte, nous devons « découvrir » leurs capacités cognitives de façon expérimentale.
Partant de ce constat, nous avons postulé que les outils développés dans le domaine de la psychologie pouvaient s’avérer pertinents pour étudier les LLMs.
Pourquoi étudier le raisonnement dans les grands modèles de langage ?
Un des objectifs principaux de la psychologie scientifique (expérimentale, comportementale et cognitive) est de tenter de comprendre les mécanismes sous-jacents aux capacités et aux comportements de réseaux de neurones extrêmement complexes : ceux des cerveaux humains.
Notre laboratoire étant spécialisé dans l’étude des biais cognitifs chez les humains, la première idée qui nous est venue à l’esprit a été de tenter de déterminer si les LLMs présentaient eux aussi des biais de raisonnement.
Étant donné le rôle que ces machines pourraient être amenées à prendre dans nos vies, comprendre comment ces machines raisonnent et prennent des décisions est fondamental. Par ailleurs, les psychologues peuvent aussi bénéficier de ces études. En effet, les réseaux de neurones artificiels, qui peuvent accomplir des tâches dans lesquelles le cerveau humain excelle (reconnaissance d’objets, traitement de la parole…) pourraient aussi servir de modèles cognitifs.
Un nombre croissant d’indices suggère notamment que les réseaux neuronaux mis en œuvre dans les LLM fournissent non seulement des prédictions précises concernant l’activité neuronale impliquée dans des processus tels que la vision et le traitement du langage.
Ainsi, il a été notamment démontré que l’activité neuronale des réseaux de neurones entraînés à la reconnaissance d’objets corrèle significativement avec l’activité neuronale enregistrée dans le cortex visuel d’un individu réalisant la même tâche.
C’est aussi le cas en ce qui concerne la prédiction de données comportementales, notamment en apprentissage.
Des performances qui ont fini par surpasser celles des humains
Lors de nos travaux, nous nous sommes principalement focalisés sur les LLMs de OpenAI (la société à l’origine du modèle de langage GPT-3, utilisé dans les premières versions de ChatGPT), car ces LLMs étaient à l’époque les plus performants dans le paysage. Nous avons testé plusieurs versions de GPT-3, ainsi que ChatGPT et GPT-4.
Pour tester ces modèles, nous avons développé une interface permettant d’envoyer des questions et de collecter des réponses des modèles de façon automatique, ce qui nous a permis d’acquérir une grande quantité de données.
L’analyse de ces données a révélé que les performances de ces LLMs présentaient des profils de comportement pouvant être classés en trois catégories.
Les modèles plus anciens étaient tout simplement incapables de répondre aux questions de façon sensée.
Les modèles intermédiaires répondaient aux questions, mais s’engageaient souvent dans des raisonnements intuitifs qui les menait à faire des erreurs, telles que celles retrouvées chez les êtres humains. Ils semblaient privilégier « le système 1 », évoqué par le psychologue et prix Nobel d’économie Daniel Kahneman dans sa théorie des modes de pensée.
Chez l’être humain, le système 1 est un mode de raisonnement rapide, instinctif et émotionnel, tandis que le système 2 est plus lent, plus réfléchi et plus logique. Bien qu’il soit davantage sujet aux biais de raisonnement, le système 1 serait néanmoins privilégié, car plus rapide et moins coûteux en énergie que le système 2.
Voici un exemple des erreurs de raisonnement que nous avons testées, tiré du « Cognitive Reflection Test » :
Question posée : Une batte et une balle coûtent 1,10 dollar au total. La batte coûte 1,00 dollar de plus que la balle. Combien coûte la balle ?
Réponse intuitive (« système 1 ») : 0,10 dollar ;
Réponse correcte (« système 2 ») : 0,05 dollar.
Enfin, la toute dernière génération (ChatGPT et GPT-4) présentait des performances qui surpassaient celles des êtres humains.
Nos travaux ont donc permis d’identifier une trajectoire positive dans les performances des LLMs, que l’on pourrait concevoir comme une trajectoire « développementale » ou « évolutionnaire » où un individu ou une espèce acquiert de plus en plus de compétences avec le temps.
Des modèles qui peuvent s’améliorer
Nous nous sommes demandé s’il était possible d’améliorer les performances des modèles présentant des performances « intermédiaires » (c’est-à-dire ceux qui répondaient aux questions, mais présentaient des biais cognitifs). Nous les avons pour cela « incités » à aborder le problème qui les avait induits en erreur de façon plus analytique, ce qui s’est traduit par une augmentation des performances.
La façon la plus simple d’améliorer les performances des modèles est de simplement leur demander de prendre du recul en leur demandant de « réfléchir pas à pas » avant de leur poser la question. Une autre solution très efficace consiste à leur montrer un exemple d’un problème correctement résolu, ce qui induit une forme d’apprentissage rapide (« one shot », en anglais)
Ces résultats indiquent encore une fois que les performances de ces modèles ne sont pas figées, mais plastiques ; au sein d’un même modèle, des modifications apparemment neutres du contexte peuvent modifier les performances, un peu comme chez l’humain, où les effets de cadrage et de contexte (tendance à être influencé par la façon dont l’information est présentée) sont très répandus.
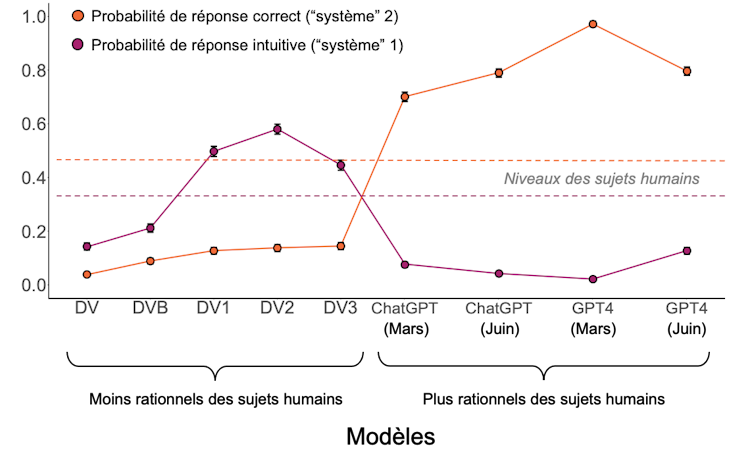
En revanche, nous avons aussi constaté que les comportements des LLMs diffèrent de ceux des humains en de nombreux points. D’une part, parmi la douzaine de modèles testés, nous avons rencontré des difficultés à en trouver un qui soit capable d’approximer correctement le niveau de réponses correctes fournies, aux mêmes questions, par des êtres humains. Dans nos expériences, les résultats des modèles IA étaient soit moins bons, soit meilleurs). D’autre part, en regardant plus en détail les questions posées, celles qui posaient le plus de difficultés aux humains n’étaient pas nécessairement perçues comme les plus difficiles par les modèles.
Ces observations suggèrent que nous ne pouvons pas substituer les sujets humains par des LLMs pour comprendre la psychologie humaine, comme certains auteurs l’ont suggéré.
Enfin, nous avons aussi observé un fait relativement inquiétant du point de vue de la reproductibilité scientifique. Nous avons testé ChatGPT et GPT-4 à quelques mois d’intervalle et nous avons observé que leurs performances avaient changé, mais pas nécessairement pour le mieux.
Cela correspond au fait que OpenAI a légèrement modifié leurs modèles, sans forcément en informer la communauté scientifique. Travailler avec des modèles propriétaires n’est pas à l’abri de ces aléas. Pour cette raison, nous pensons que le futur de la recherche (cognitive ou autre) sur les LLMs devrait se baser sur des modèles ouverts et transparents pour garantir plus de contrôle.