


A pesar del auge del feminismo en los últimos años, los efectos negativos y generalizados del sexismo en la inteligencia artificial suelen ser subestimados.
Lejos de ser minoritario, el sexismo, y la discriminación que éste genera, impregna hoy en día el funcionamiento de los algoritmos de inteligencia artificial. Esto es un problema porque cada vez usamos más algoritmos para tomar decisiones cruciales sobre nuestras vidas. Por ejemplo, quién puede acceder y quién no a una entrevista de trabajo o a una hipoteca.
Sexismo en los algoritmos
La literatura científica que estudia la presencia de sesgos y errores en los algoritmos de aprendizaje automático está todavía en sus primeras etapas, pero los resultados son muy preocupantes.
Se ha comprobado que los algoritmos heredan los sesgos de género que imperan en nuestra sociedad. Como veremos a continuación, los sesgos humanos llevan a errores sistemáticos en los algoritmos. Es más, a menudo estos sesgos tienden a incrementarse debido a la gran cantidad de datos que manejan los algoritmos y a su uso generalizado.
Por ejemplo, en un estudio en el que se aplicaron técnicas de aprendizaje automático para entrenar a una inteligencia artificial utilizando Google News, se resolvió la analogía “hombre es a programador de ordenadores lo que mujer es a x”. La respuesta automática fue que “x = ama de casa”.
De manera similar, otro hallazgo inquietante fue el que se observó en un algoritmo entrenado con texto tomado de internet. Éste asociaba nombres femeninos como Sarah con palabras atribuidas a la familia, tales como padres y boda. En cambio, nombres masculinos como John tenían asociaciones más fuertes con palabras atribuidas al trabajo, como profesional y salario.
Amazon también tuvo que eliminar su algoritmo de selección de personal porque mostraba un fuerte sesgo de género, penalizando los CV que contenían la palabra mujer.
El sexismo también se cuela en los algoritmos de búsqueda de imágenes. Por ejemplo, una investigación mostró que en Bing se recuperan fotos de mujeres más a menudo al utilizar en las búsquedas palabras con rasgos cálidos, como por ejemplo, sensible o emocional. Por el contrario, palabras con rasgos de competencia, tales como inteligente o racional, están más representados por fotos de hombres. Es más, al buscar la palabra persona se recuperan más a menudo fotos de hombres que de mujeres.
En otro trabajo se observó que el algoritmo asociaba imágenes de compras y cocinas con mujeres. Así, deducía que “si está en la cocina, es mujer” la mayor parte de las veces. En cambio, asociaba imágenes de entrenamiento físico con hombres.
Además de los datos de texto y las imágenes, las entradas e interacciones que realizan los usuarios también refuerzan y nutren el aprendizaje de sesgos de los algoritmos. Un ejemplo de ello lo confirmó un trabajo en el que se observaba que los temas relacionados con la familia y las relaciones románticas se discuten mucho más frecuentemente en los artículos de Wikipedia sobre las mujeres que sobre los hombres. Además, la biografía de mujeres tiende a estar más vinculada (mediante enlaces) a la de los hombres que viceversa.
Sesgo algorítmico en lenguas con género
Hasta la fecha los estudios que se han centrado en examinar el sesgo de género lo han hecho casi exclusivamente analizando el funcionamiento de los algoritmos con el idioma inglés. Sin embargo, esta lengua no tiene género gramatical.
En inglés, la maestra simpática y el maestro simpático se dice igual: the nice teacher. Por tanto, cabe preguntarse qué ocurre con lenguas como el español, que sí tiene género gramatical.
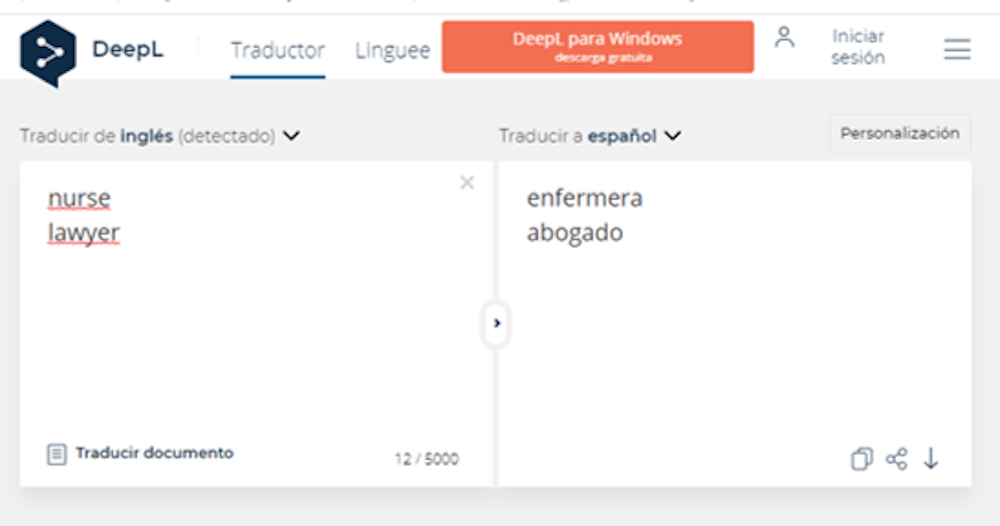
La investigación al respecto ha encontrado sesgos de género al traducir del inglés a idiomas con género gramatical como el nuestro. Por ejemplo, un estudio mostró que al traducir la palabra lawyer del inglés al español había una asociación automática más fuerte con la palabra abogado que abogada. Por el contrario, la palabra nurse estaba más relacionada con la palabra enfermera que enfermero. En principio tendría que haber asociado ambas traducciones con idéntica probabilidad.
A pesar de las numerosas críticas de los últimos años, los sesgos que se producen al traducir desde una lengua sin género gramatical, como el inglés, a una con género gramatical, como el español, se siguen dando hoy en día en algunos traductores automáticos como, por ejemplo, DeepL (ver Figura 1).
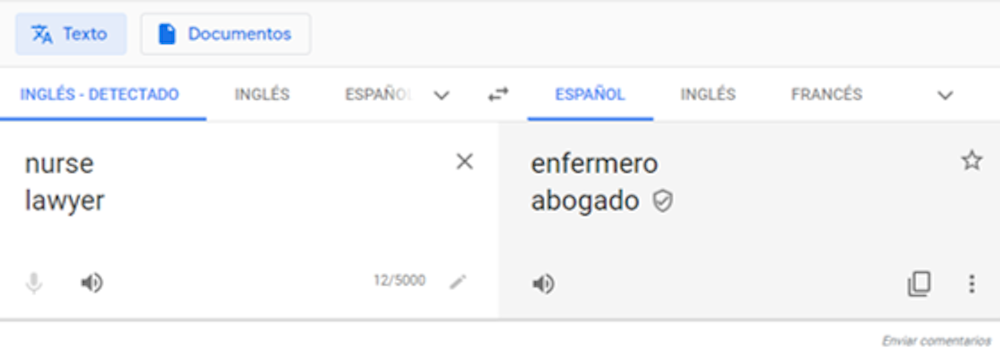
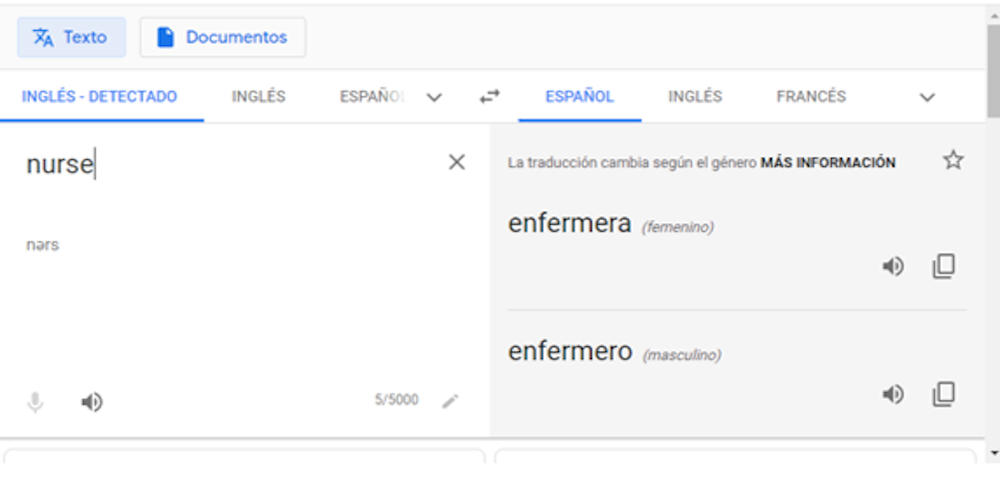
Algunos traductores como Google Translate han introducido correcciones. Hoy en día traducen con el masculino genérico un conjunto de palabras (ver Figura 2), pero han incorporado también el desdoblamiento por género femenino y masculino de palabras e incluso frases cortas (ver Figura 3).
¿Qué solución tiene?
En la actualidad, se están desarrollando iniciativas y estándares destinados a abordar el problema de los sesgos algorítmicos. Pero, por el momento, la mayor parte de los sistemas de inteligencia artificial presenta sesgos.
La investigación sugiere que subestimamos los sesgos presentes en las máquinas e incluso tendemos a considerar más justas y preferir las recomendaciones de los algoritmos a las de los humanos. Pero, ¿realmente queremos delegar nuestras decisiones en algoritmos que asocian mujer con ama de casa? IBM predice que “sólo la inteligencia artificial que esté libre de sesgos sobrevivirá”.