


L’élection du Président de la République française constitue un exemple important de mode de scrutin à deux tours. L’issue des deux tours est évidemment liée, et les résultats du premier permettent d’avoir une idée de l’issue du second tour.
Il est en effet plausible que les électeurs ayant voté au premier tour pour l’un des candidats qualifiés au second tour confortent leur choix. En revanche, le vote des électeurs ayant accordé au premier tour leur suffrage à des candidats éliminés du second tour est entaché de plus d’incertitude. Le choix de ces électeurs n’est pas totalement aléatoire car il est dépend fortement de la proximité idéologique et partisane entre le candidat pour lequel ils ont voté au premier tour et chacun des candidats qualifiés.
Reports de vote
Les choix électoraux au second tour de scrutin des électeurs ayant voté au premier tour pour un candidat éliminé sont appelés les « reports de vote ». Ils sont généralement appréhendés de manière agrégée et sous forme de proportions : telle fraction de l’électorat de premier tour de tel candidat se reporte sur tel candidat au second tour.
La connaissance de ces reports de votes comporte principalement deux intérêts. D’une part, les reports de votes constituent un élément de science politique à part entière. Ils renseignent au sujet du positionnement respectif des électorats, de l’ordre de priorité qu’ils attribuent aux différentes thématiques du débat public, de leur fidélité partisane et de leur degré d’information politique. À ce titre, ils sont susceptibles d’intéresser les formations politiques et les candidats eux-mêmes dans l’élaboration ex ante de leurs stratégies électorales et dans leur évaluation ex post. D’autre part, connaître les reports de votes permet de construire des prédictions des résultats du second tour à l’issue du premier tour.
Les estimations de reports de votes publiées, notamment dans la presse, résultent le plus souvent de sondages effectués directement auprès des électeurs. L’estimation produite par le sondage va dépendre de l’échantillon tiré, avec pour corollaire l’existence d’un inévitable écart entre le paramètre et son estimation. Cet écart est quantifié en terme de probabilité associée à un sondage. Cependant les tailles d’échantillon utilisées et le très faible taux de réponse génèrent de telles incertitudes qu’il est difficile de conclure quoi que ce soit à partir de ces sondages.
Pour résumer rapidement, l’évolution (positive) de la présentation des sondages, et en particulier la présentation de termes de probabilité, doit s’accompagner d’une évolution des méthodes et en particulier des tailles d’échantillon. Il est important de rappeler que les intervalles de confiance n’ont aucune valeur prédictive (et donc aucune validité testable ex-post). Par exemple, comment lire le graphique ci-dessous sur les intentions de vote au premier tour :
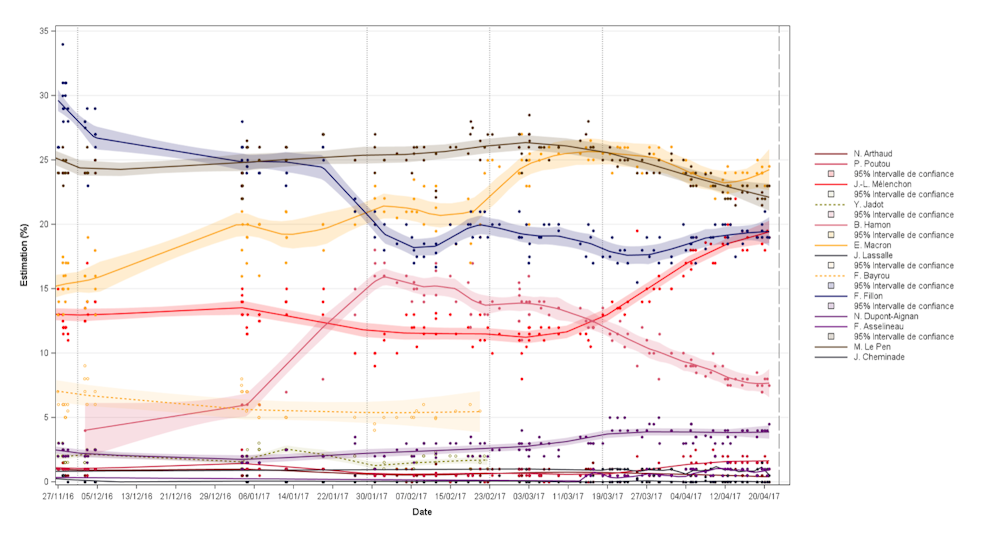
Doit-on comprendre que fin janvier, 16 % des électeurs affirmaient vouloir voter pour Benoît Hamon, et qu’avec 95 chances sur 100 cette proportion était comprise entre 15 % et 17 % ? Un mois plus tard, il était à 14 %. A-t-il perdu des intentions de votes ? ou bien peut-on imaginer que des électeurs indécis fin janvier (et non comptabilisés) aient décidé de voter pour une autre alternative ? Les pourcentages ne sont pas, ici, relatifs à la même quantité.
Mais revenons à l’estimation des reports de voix, outils-clés pour prévoir la probabilité de gagner au second tour. Les estimations produites à l’aide d’outils mathématiques, à partir des résultats de scrutin par bureaux de vote, restent rares dans la presse mais c’est une source importante d’études en science politique. Essayons de voir le principe.
En démocratie, le vote de chaque électeur est confidentiel. À chaque tour d’une élection, seul le résultat agrégé des votes est connu, et le niveau le plus fin d’agrégation est donné par le bureau de vote. Les reports d’un vote à un autre sont inconnus, et leur estimation à partir des résultats agrégés nécessite de définir un modèle statistique. En effet, la décision individuelle de chaque électeur n’obéit à aucune fonction déterministe.
On résume souvent ce principe sous la formule « le vote est privé, les votes sont publics ». Néanmoins ce principe ouvre grand la porte au paradoxe de Simpson (on parle aussi d’erreur écologique) : à cause de la distribution hétérogène de l’échantillon, regrouper les données pointe une tendance qui peut être fausse, et qui disparaît si on analyse les données en séparant selon le facteur de confusion. L’utilisation de données socio-démographiques est donc importante.
Estimer la probabilité qu’un candidat gagne une élection
Tout d’abord, notons que l’élection mobilise un corps électoral composé de N électeurs répartis dans K bureaux de vote, à raison de Nk électeurs dans le bureau k. Le nombre d’électeurs dans chaque bureau demeure identique lors des deux tours. Pour chaque tour et chaque électeur, le vote peut être vu comme la sélection d’une unique modalité dans un ensemble de choix commun à tous les électeurs. Pour l’élection présidentielle de 2017, il y a I=13 choix possibles au premier tour : s’abstenir, voter blanc ou pour un des onze candidats ; et J = 4 choix possibles au second : s’abstenir, voter blanc ou pour les candidats Macron ou Le Pen.
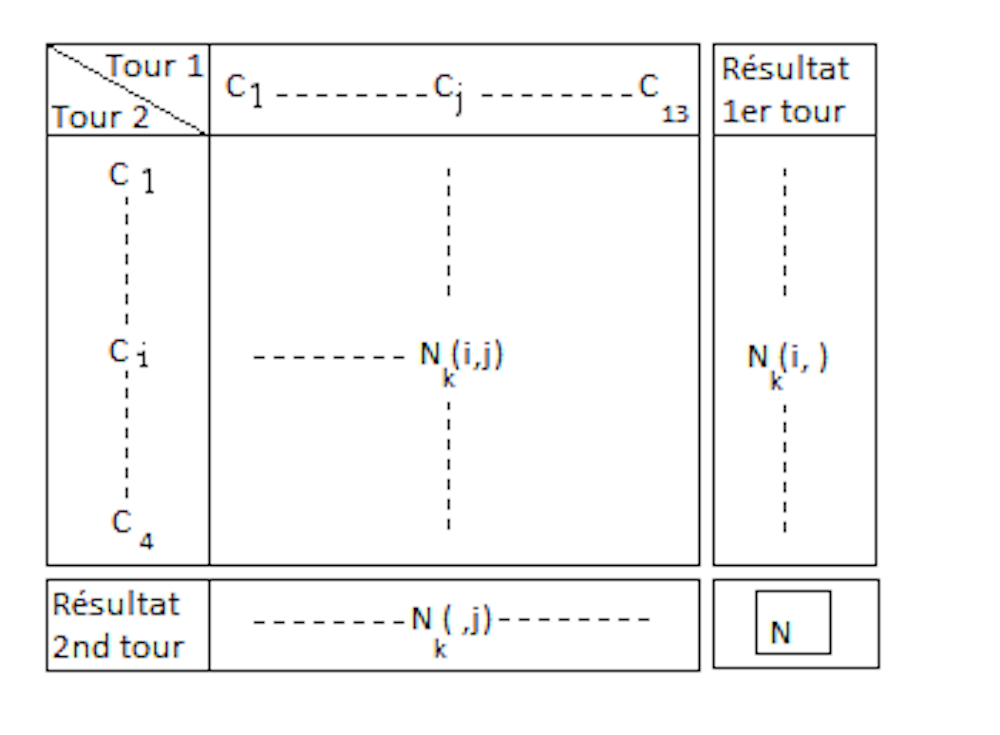
Étant donné l’hypothèse de stabilité du corps électoral, on peut construire pour chaque bureau k, un tableau croisé (on parle de tableau de contingence) constitué des nombres Nk(i,j) d’électeurs ayant opté pour le choix i au premier tour et j au second, à l’issu du dépouillement du second tour. De ces tableaux, seules les marges suivant les lignes Nk(i,) et suivant les colonnes Nk(,j) sont connues et correspondent respectivement aux résultats du premier et du second tour. Les conditions de vote (isoloir, bulletin sous enveloppe, dépouillement à la fin…) font que lors du scrutin, les électeurs sont globalement ignorants des choix des autres électeurs, à l’exception de l’abstention qui fait l’objet d’une estimation communiquée et révisée régulièrement en cours de journée. Par conséquent, il semble relativement raisonnable de considérer que les décisions de vote sont prises simultanément et qu’elles sont donc indépendantes entre électeurs.
Les probabilités de report du candidat i au candidat j diffèrent a priori entre électeurs d’un même bureau et entre bureaux. Même si le résultat final était connu, les différentes manières d’estimer ces probabilités soulèvent des problèmes complexes, résolus en mobilisant de nombreuses techniques algorithmiques. Estimer la probabilité qu’un électeur ayant fait un des 13 choix possibles (par exemple l’abstention) au premier tour en fasse un des 4 possibles au second (par exemple l’abstention) est un exercice compliqué mais indispensable si on souhaite vraiment estimer la probabilité de victoire d’un candidat. Et à part enfoncer des portes ouvertes, on ne peut pas dire grand-chose : si quelqu’un dit qu’une pièce est pipée, et à 80 % de chances de tomber sur « pile », le fait qu’elle tombe une fois sur « pile » ne signifiera pas qu’il a « raison », pas plus que tomber sur « face » ne signifiera qu’il a « tort ».
En statistique, c’est la répétition qui permet de savoir si l’estimation d’une probabilité est pertinente. Or c’est le propre d’une élection que de ne se produire qu’une fois.
Pour aller plus loin : Søren Risbjerg Thompsen, « Danish Elections 1920-79 : A logit Approach to Ecological Analysis and Inference » (1987) et Fendrich, L’Hour et Rateau, « Reports de votes entre les deux tours d’une élection présidentielle : estimation statistique et sociologie électorale » (2014).